
Branch of machine learning
POPULARITY

6 episodes with deep neural networks

6 episodes with deep neural networks

4 episodes with deep neural networks

2 episodes with deep neural networks

3 episodes with deep neural networks

3 episodes with deep neural networks

2 episodes with deep neural networks

9 episodes with deep neural networks

2 episodes with deep neural networks
• Support & get perks!• Proudly sponsored by PyMC Labs! Get in touch at alex.andorra@pymc-labs.com• Intro to Bayes and Advanced Regression courses (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work !Chapters:00:00 Exploring Generative AI and Scientific Modeling10:27 Understanding Simulation-Based Inference (SBI) and Its Applications15:59 Diffusion Models in Simulation-Based Inference19:22 Live Coding Session: Implementing Baseflow for SBI34:39 Analyzing Results and Diagnostics in Simulation-Based Inference46:18 Hierarchical Models and Amortized Bayesian Inference48:14 Understanding Simulation-Based Inference (SBI) and Its Importance49:14 Diving into Diffusion Models: Basics and Mechanisms50:38 Forward and Backward Processes in Diffusion Models53:03 Learning the Score: Training Diffusion Models54:57 Inference with Diffusion Models: The Reverse Process57:36 Exploring Variants: Flow Matching and Consistency Models01:01:43 Benchmarking Different Models for Simulation-Based Inference01:06:41 Hierarchical Models and Their Applications in Inference01:14:25 Intervening in the Inference Process: Adding Constraints01:25:35 Summary of Key Concepts and Future DirectionsThank you to my Patrons for making this episode possible!Links from the show:- Come meet Alex at the Field of Play Conference in Manchester, UK, March 27, 2026!- Jonas's Diffusion for SBI Tutorial & Review (Paper & Code)- The BayesFlow Library- Jonas on LinkedIn- Jonas on GitHub- Further reading for more mathematical details: Holderrieth & Erives- 150 Fast Bayesian Deep Learning, with David Rügamer, Emanuel Sommer & Jakob Robnik- 107 Amortized Bayesian Inference with Deep Neural Networks, with Marvin Schmitt

פרק מספר 505 של רברס עם פלטפורמה - באמפרס מספר 89, שהוקלט ב-13 בנובמבר 2025, רגע אחרי כנס רברסים 2025 [יש וידאו!]: רן, דותן ואלון (והופעת אורח של שלומי נוח!) באולפן הוירטואלי עם סדרה של קצרצרים מרחבי האינטרנט: הבלוגים, ה-GitHub-ים, ה-Claude-ים וה-GPT-ים החדשים מהתקופה האחרונה.
Sign up for Alex's first live cohort, about Hierarchical Model building!Get 25% off "Building AI Applications for Data Scientists and Software Engineers"Proudly sponsored by PyMC Labs, the Bayesian Consultancy. Book a call, or get in touch!Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work!Visit our Patreon page to unlock exclusive Bayesian swag ;)Takeaways:Why GPs still matter: Gaussian Processes remain a go-to for function estimation, active learning, and experimental design – especially when calibrated uncertainty is non-negotiable.Scaling GP inference: Variational methods with inducing points (as in GPflow) make GPs practical on larger datasets without throwing away principled Bayes.MCMC in practice: Clever parameterizations and gradient-based samplers tighten mixing and efficiency; use MCMC when you need gold-standard posteriors.Bayesian deep learning, pragmatically: Stochastic-gradient training and approximate posteriors bring Bayesian ideas to neural networks at scale.Uncertainty that ships: Monte Carlo dropout and related tricks provide fast, usable uncertainty – even if they're approximations.Model complexity ≠ model quality: Understanding capacity, priors, and inductive bias is key to getting trustworthy predictions.Deep Gaussian Processes: Layered GPs offer flexibility for complex functions, with clear trade-offs in interpretability and compute.Generative models through a Bayesian lens: GANs and friends benefit from explicit priors and uncertainty – useful for safety and downstream decisions.Tooling that matters: Frameworks like GPflow lower the friction from idea to implementation, encouraging reproducible, well-tested modeling.Where we're headed: The future of ML is uncertainty-aware by default – integrating UQ tightly into optimization, design, and deployment.Chapters:08:44 Function Estimation and Bayesian Deep Learning10:41 Understanding Deep Gaussian Processes25:17 Choosing Between Deep GPs and Neural Networks32:01 Interpretability and Practical Tools for GPs43:52 Variational Methods in Gaussian Processes54:44 Deep Neural Networks and Bayesian Inference01:06:13 The Future of Bayesian Deep Learning01:12:28 Advice for Aspiring Researchers
This Week in Machine Learning & Artificial Intelligence (AI) Podcast
Today, we're joined by Charles Martin, founder of Calculation Consulting, to discuss Weight Watcher, an open-source tool for analyzing and improving Deep Neural Networks (DNNs) based on principles from theoretical physics. We explore the foundations of the Heavy-Tailed Self-Regularization (HTSR) theory that underpins it, which combines random matrix theory and renormalization group ideas to uncover deep insights about model training dynamics. Charles walks us through WeightWatcher's ability to detect three distinct learning phases—underfitting, grokking, and generalization collapse—and how its signature “layer quality” metric reveals whether individual layers are underfit, overfit, or optimally tuned. Additionally, we dig into the complexities involved in fine-tuning models, the surprising correlation between model optimality and hallucination, the often-underestimated challenges of search relevance, and their implications for RAG. Finally, Charles shares his insights into real-world applications of generative AI and his lessons learned from working in the field. The complete show notes for this episode can be found at https://twimlai.com/go/734.

Host Chris Adams is joined by Charles Tripp and Dawn Nafus to explore the complexities of measuring AI's environmental impact from a novice's starting point. They discuss their research paper, A Beginner's Guide to Power and Energy Measurement and Estimation for Computing and Machine Learning, breaking down key insights on how energy efficiency in AI systems is often misunderstood. They discuss practical strategies for optimizing energy use, the challenges of accurate measurement, and the broader implications of AI's energy demands. They also highlight initiatives like Hugging Face's Energy Score Alliance, discuss how transparency and better metrics can drive more sustainable AI development and how they both have a commonality with eagle(s)!

AI copilots have changed a range of professions, from healthcare to finance, by automating tasks and enhancing productivity. But can copilots also create value for people performing more mechanical, hands-on tasks or figuring out how to bring factories online? In this episode, Barbara welcomes Olympia Brikis, Director of AI Research at Siemens, to show how generative AI is shaping new industrial tech jobs at the convergence of the real and digital worlds. Olympia sheds light on the unique career opportunities in AI and what it takes to thrive in this dynamic, emerging field. Whether you're a tech enthusiast or someone curious about tech careers, this episode offers a unique perspective on how AI is reshaping the landscape of mechanical and industrial professions. Tune in to learn about the exciting innovations and the future of AI in industry! Show notes In this episode, Barbara asks Olympia to share some resources that can help all of us get smarter on industrial AI. Here are Olympia's recommendations: For everyone just getting started with (Generative) AI: Elements of AI – great for learning how AI work and what it is https://www.elementsofai.com/ Generative AI for Everyone: https://www.coursera.org/learn/generative-ai-for-everyone Co-Intelligence: Living and Working with AI, by Ethan Mollick For those want to dive deeper into the technical aspects of Deep Neural Networks and Generative AI: Deep Learning Specialization: https://www.coursera.org/specializations/deep-learning Stanford University Lecture CS336: Language Modeling from Scratch https://stanford-cs336.github.io/spring2024/
Send us a textShort Summary: A deep dive into the enigmatic world of sleep, exploring its biological functions, evolutionary origins, and the diverse manifestations across different species.Note: Podcast episodes are fully available to paid subscribers on the M&M Substack and on YouTube. Partial versions are available elsewhere.About the Guest: Vlad Vyazovskiy, PhD is a Professor of Sleep Physiology at the Department of Physiology, Anatomy, and Genetics at Oxford University.Key Takeaways:Sleep as a Mystery: Despite extensive research, the fundamental reason why animals sleep remains elusive, with no comprehensive theory yet agreed upon.Local Sleep Phenomenon: Sleep might not be a whole-brain event; even within a sleeping brain, different areas can be in different states of activity or rest.Sleep in Animals: Sleep varies widely among species, from micro-sleeps in penguins to unihemispheric sleep in dolphins, suggesting sleep could serve multiple, context-dependent functions.Synaptic Homeostasis: The hypothesis suggests that sleep could be crucial for renormalizing synaptic connections formed during wakefulness, although this idea is still under scrutiny.Hibernation & Torpor: These states relate to sleep but involve significant metabolic changes, possibly acting as survival mechanisms by conserving energy and reducing detectability by predators.Psychedelics & Sleep: Research shows psychedelics like 5-MeO-DMT can induce states where animals show signs of sleep in their brain activity while physically active, hinting at complex interactions between brain states and consciousness.Related episodes:M&M #43: Sleep, Dreaming, Deep Neural Networks, Machine Learning & Artificial Intelligence, Overfitted Brain Hypothesis, Evolution of Fiction & Art | Erik HoelM&M #16: Sleep, Dreams, Memory & the Brain | Bob Stickgold*Not medical advice.Support the showAll episodes (audio & video), show notes, transcripts, and more at the M&M Substack Affiliates: MASA Chips—delicious tortilla chips made from organic corn and grass-fed beef tallow. No seed oils or artificial ingredients. Use code MIND for 20% off. Lumen device to optimize your metabolism for weight loss or athletic performance. Use code MIND for 10% off. Athletic Greens: Comprehensive & convenient daily nutrition. Free 1-year supply of vitamin D with purchase. KetoCitra—Ketone body BHB + potassium, calcium & magnesium, formulated with kidney health in mind. Use code MIND20 for 20% off any subscription. Learn all the ways you can support my efforts
Subscriber-only episodeSend us a textShort Summary: A deep dive into the enigmatic world of sleep, exploring its biological functions, evolutionary origins, and the diverse manifestations across different species.Note: Podcast episodes are fully available to paid subscribers on the M&M Substack and on YouTube. Partial versions are available elsewhere.About the Guest: Vlad Vyazovskiy, PhD is a Professor of Sleep Physiology at the Department of Physiology, Anatomy, and Genetics at Oxford University.Key Takeaways:Sleep as a Mystery: Despite extensive research, the fundamental reason why animals sleep remains elusive, with no comprehensive theory yet agreed upon.Local Sleep Phenomenon: Sleep might not be a whole-brain event; even within a sleeping brain, different areas can be in different states of activity or rest.Sleep in Animals: Sleep varies widely among species, from micro-sleeps in penguins to unihemispheric sleep in dolphins, suggesting sleep could serve multiple, context-dependent functions.Synaptic Homeostasis: The hypothesis suggests that sleep could be crucial for renormalizing synaptic connections formed during wakefulness, although this idea is still under scrutiny.Hibernation & Torpor: These states relate to sleep but involve significant metabolic changes, possibly acting as survival mechanisms by conserving energy and reducing detectability by predators.Psychedelics & Sleep: Research shows psychedelics like 5-MeO-DMT can induce states where animals show signs of sleep in their brain activity while physically active, hinting at complex interactions between brain states and consciousness.Related episodes:M&M #43: Sleep, Dreaming, Deep Neural Networks, Machine Learning & Artificial Intelligence, Overfitted Brain Hypothesis, Evolution of Fiction & Art | Erik HoelM&M #16: Sleep, Dreams, Memory & the Brain | Bob Stickgold*Not medical advice.All episodes (audio & video), show notes, transcripts, and more at the M&M Substack Affiliates: MASA Chips—delicious tortilla chips made from organic corn and grass-fed beef tallow. No seed oils or artificial ingredients. Use code MIND for 20% off. Lumen device to optimize your metabolism for weight loss or athletic performance. Use code MIND for 10% off. Athletic Greens: Comprehensive & convenient daily nutrition. Free 1-year supply of vitamin D with purchase. KetoCitra—Ketone body BHB + potassium, calcium & magnesium, formulated with kidney health in mind. Use code MIND20 for 20% off any subscription. Learn all the ways you can support my efforts
Send us a Text Message.About the guest: Luis de Lecea, PhD is a neurobiologist whose lab at Stanford University studies the neural basis of sleep & wakefulness in animals.Episode summary: Nick and Dr. de Lecea discuss: the neural basis of sleep; sleep architecture & sleep phases (NREM vs. REM sleep); orexin/hypocretin neurons & the lateral hypothalamus; cortisol & stress; circadian rhythms; neuromodulators (norepinephrine, dopamine, etc); sleep across animal species; sleep drugs; ultrasound technology; and more.Related episodes:Sleep, Dreaming, Deep Neural Networks, Machine Learning & Artificial Intelligence, Overfitted Brain Hypothesis, Evolution of Fiction & Art | Erik Hoel | #43Consciousness, Anesthesia, Coma, Vegetative States, Sleep Pills (Ambien), Ketamine, AI & ChatGPT | Alex Proekt | #101*This content is never meant to serve as medical advice.Support the Show.All episodes (audio & video), show notes, transcripts, and more at the M&M Substack Try Athletic Greens: Comprehensive & convenient daily nutrition. Free 1-year supply of vitamin D with purchase.Try SiPhox Health—Affordable, at-home bloodwork w/ a comprehensive set of key health marker. Use code TRIKOMES for a 10% discount.Try the Lumen device to optimize your metabolism for weight loss or athletic performance. Use code MIND for 10% off.Learn all the ways you can support my efforts
Proudly sponsored by PyMC Labs, the Bayesian Consultancy. Book a call, or get in touch!My Intuitive Bayes Online Courses1:1 Mentorship with meIn this episode, Marvin Schmitt introduces the concept of amortized Bayesian inference, where the upfront training phase of a neural network is followed by fast posterior inference.Marvin will guide us through this new concept, discussing his work in probabilistic machine learning and uncertainty quantification, using Bayesian inference with deep neural networks. He also introduces BaseFlow, a Python library for amortized Bayesian workflows, and discusses its use cases in various fields, while also touching on the concept of deep fusion and its relation to multimodal simulation-based inference.A PhD student in computer science at the University of Stuttgart, Marvin is supervised by two LBS guests you surely know — Paul Bürkner and Aki Vehtari. Marvin's research combines deep learning and statistics, to make Bayesian inference fast and trustworthy. In his free time, Marvin enjoys board games and is a passionate guitar player.Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work at https://bababrinkman.com/ !Thank you to my Patrons for making this episode possible!Yusuke Saito, Avi Bryant, Ero Carrera, Giuliano Cruz, Tim Gasser, James Wade, Tradd Salvo, William Benton, James Ahloy, Robin Taylor,, Chad Scherrer, Zwelithini Tunyiswa, Bertrand Wilden, James Thompson, Stephen Oates, Gian Luca Di Tanna, Jack Wells, Matthew Maldonado, Ian Costley, Ally Salim, Larry Gill, Ian Moran, Paul Oreto, Colin Caprani, Colin Carroll, Nathaniel Burbank, Michael Osthege, Rémi Louf, Clive Edelsten, Henri Wallen, Hugo Botha, Vinh Nguyen, Marcin Elantkowski, Adam C. Smith, Will Kurt, Andrew Moskowitz, Hector Munoz, Marco Gorelli, Simon Kessell, Bradley Rode, Patrick Kelley, Rick Anderson, Casper de Bruin, Philippe Labonde, Michael Hankin, Cameron Smith, Tomáš Frýda, Ryan Wesslen, Andreas Netti, Riley King, Yoshiyuki Hamajima, Sven De Maeyer, Michael DeCrescenzo, Fergal M, Mason Yahr, Naoya Kanai, Steven Rowland, Aubrey Clayton, Jeannine Sue, Omri Har Shemesh, Scott Anthony Robson, Robert Yolken, Or Duek, Pavel Dusek, Paul Cox, Andreas Kröpelin, Raphaël R, Nicolas Rode, Gabriel Stechschulte, Arkady, Kurt TeKolste, Gergely Juhasz, Marcus Nölke, Maggi Mackintosh, Grant Pezzolesi, Avram Aelony, Joshua Meehl, Javier Sabio, Kristian Higgins, Alex Jones, Gregorio Aguilar, Matt Rosinski, Bart Trudeau, Luis Fonseca, Dante Gates, Matt Niccolls, Maksim Kuznecov, Michael Thomas, Luke Gorrie, Cory Kiser, Julio, Edvin Saveljev, Frederick Ayala, Jeffrey Powell, Gal Kampel, Adan Romero, Will Geary and Blake Walters.Visit https://www.patreon.com/learnbayesstats to unlock exclusive Bayesian swag ;)Takeaways:Amortized Bayesian inference...

Today we sat down with Diego and a little bit more about him: I am a Data Scientist / ML (Maching Learning) engineer, born in Suriname, South America, I also have a background in music production. Where I've built a business around it, with a global client base. I transitioned into tech first starting and working as a front end developer and then transitioned again into machine learning. Link to the Simplilearn / Caltech video: https://www.youtube.com/watch?v=Qlw1tqY4_vc&t=19s Link to my Mindkeyz music production channel: https://www.youtube.com/@Mindkeyz Ramblings of a Designer podcast is a monthly design news and discussion podcast hosted by Laszlo Lazuer and Terri Rodriguez-Hong (@flaxenink, insta: flaxenink.design). Facebook:https://www.facebook.com/Ramblings-of-a-Designer-Podcast-2347296798835079/ Send us feedback! ramblingsofadesignerpod@gmail.com, Support us on Patreon! patreon.com/ramblingsofadesigner We would love to hear from you!

VA-ECMO outcome scores have been previously developed and used extensively for risk adjustment, patient prognostication, and quality control across time and centres. The limitation of such scores is the derivation by using traditional statistical methods which are not capable of covering the complexity of ECMO outcomes. The Extracorporeal Life Support Organization Member Centres have developed a study where they aimed to leverage a large international patient cohort to develop and validate an AI-driven tool for predicting in-hospital mortality of VA-ECMO. The tool was derived entirely from pre-ECMO variables, allowing for mortality prediction immediately after ECMO initiation.To learn more about this study listen to the podcast.

An Interview with Kevin Winthrop_ Three Questions About COVID 19 Biologics in RA_ Mechanisms of Delivery Over Mechanisms of Action_ (1) Deep Neural Networks and Radiographic Progression in AxSpA Difficult to Treat axSpA Does GnRHa Reduce Premature Ovarian Insufficiency in SLE Patients on Cyclophosphamide_ Factors Associated with Discontinuation of TNFs in AxSpA From AS Patient to Rheumatologist

Amr and I met on a genAI panel and everything he said was both insightful and contrarian. Immediately, I knew I wanted to introduce him to you. Amr is a legend in the search space who, by the way, also founded Cloudera which went public in 2017 at a valuation of over $5B.Dr. Amr Awadallah is a luminary in the world of information retrieval. He's the CEO and cofounder of Vectara, a company that is revolutionizing how we find meaning across all languages of the world using the latest advances in Deep Neural Networks, Large Language Models, and Natural Language Processing. He previously served as VP of Developer Relations for Google Cloud. Prior to joining Google in Nov 2019, Amr co-founded Cloudera in 2008 and as Global CTO. He also served as vice president of product intelligence engineering at Yahoo! from 2000-2008. Amr received his PhD in EE from Stanford University, and his Bachelor and Masters Degrees from Cairo University, Egypt.Listen and learn...How Amr discovered the power of "talking to software" via LLMs while at GoogleAbout the history of new computing modalitiesAbout the current state of generative AIThe technical explanation for hallucination in LLMsHow do we mitigate bias in LLM models and prevent copyright infringementWhy a semantic understanding of queries is the next frontier in searchThe challenge faced by search providers of making money incorporating ads into LLM-based answersHow "grounded search" will fix the hallucination problemWhat is a "fact" in the era of ChatGPT?How long before we have "antivirus sofware for fact-checking" genAI propagandaHow should AI be regulated... and who is responsible for AI regulationThe next big idea in genAI Amr and I are ready to fundAmr's advice to entrepreneurs... and to himselfReferences in this episode...Eric Olson, Consensus CEO, on AI and the Future of WorkD Das, Sorcero CEO, on AI and the Future of WorkSeth Earley, Earley Information Science, on AI and the Future of WorkChatGPT for searching scientific papers

Anoop Cherian, senior principal research scientist at Mitsubishi Electric Research Laboratories, tested the reasoning skills of large language models in a set of logic puzzles to see if they are smarter than young kids.

In this talk, Murat speaks with Abhishek Pandey, Principle Research Scientist and Pharma Discovery Group Lead at AbbVie. Abhishek currently leads RAIDERS, a Pharma Discovery group integrating machine learning across all of AbbVie's working groups to augment drug discovery capabilities. Abhishek's groups work spans cheminformatics, imaging research, multi-omics, as well as the computation behind many of AbbVie's current partnerships and collaborations. We'll be exploring how the machine learning group is transforming the processes across multiple working groups at the pharmaceutical giant, AbbVie. We'll also be unravelling the story of how Abhishek began his pioneering work at AbbVie. You will learn: About Abhishek's strategy for bridging chemistry, biology and computer science expertise to integrate machine learning across AbbVie's pharma discovery processes. About Abhishek's vision for the future of drug discovery, as we explore the pressing needs of the pharmaceutical industry from both a technical and social standpoint. About Abhishek: Abhishek started his career as a software engineer at Toshiba. Following this, Abhishek began his PhD in medical engineering and image processing at the University of Arizona. This led Abhishek to become a core member of the precision medicine AI team at Tempus, developing ways to improve cancer imaging pipelines to help oncologists detect cancers more efficiently. Abhishek then joined AbbVie, where he founded the machine learning / deep learning team - the influence of which has expanded across the entire company. Things mentioned: Abhishek Pandey, Principle Research Scientist and Pharma Discovery Group Lead at AbbVie. RAIDERS: Pharma Discovery and Developmental Sciences team at AbbVie. Google Meta Toshiba Tempus Labs (now Tempus). PADME (Protein And Drug Molecule interaction prEdiction), a framework based on Deep Neural Networks, to predict real-valued interaction strength between compounds and proteins. NeurIPS Conference (Conference on Neural Information Processing Systems) InSitro Facebook Additional Materials: Watch the recording of the live event! https://www.youtube.com/watch?v=F9kADawRPOs First time hearing about Antiverse? Antiverse is an artificial intelligence-driven techbio company that specialises in antibody design against difficult-to-drug targets, including G-protein coupled receptors (GPCRs) and ion channels. Headquartered in Cardiff, UK and with offices in Boston, MA, Antiverse combines state-of-the-art machine learning techniques and advanced cell line engineering to develop de novo antibody therapeutics. With a main focus on establishing long-term partnerships, Antiverse has collaborated with two top 20 global pharmaceutical companies. In addition, they are developing a strong internal pipeline of antibodies against several challenging drug targets across various indications. For more information, please visit https://www.antiverse.io Never miss a future event! We'll notify you when there's a new event scheduled. Fill out this form to sign up for marketing communications from Antiverse. We post about upcoming events on LinkedIn and Twitter. LinkedIn: https://www.linkedin.com/company/antiverse/ Twitter (x.com) : https://twitter.com/AntiverseHQ

Emily speaks with cardiologist Eric Topol about his 2019 book Deep Medicine, which explores the potential for AI to enhance medical decision-making, improve patient outcomes, and restore the doctor-patient relationship. Find show notes, transcript, and more at thenocturnists.com.

Fabien Allo highlights his award-winning article, "Characterization of a carbonate geothermal reservoir using rock-physics-guided deep neural networks." In this episode with host Andrew Geary, Fabien shares the potential of deep neural networks (DNNs) in integrating seismic data for reservoir characterization. He explains why DNNs have yet to be widely utilized in the energy industry and why utilizing a training set was key to this study. Fabien also details why they did not include any original wells in the final training set and the advantages of neural networks over seismic inversion. He closes with how this method of training neural networks on synthetic data might be useful beyond the application to a geothermal study. This episode is an exciting opportunity to hear directly from an award-winning author on some of today's most cutting-edge geophysics tools. Listen to the full archive at https://seg.org/podcast. RELATED LINKS * Fabien Allo, Jean-Philippe Coulon, Jean-Luc Formento, Romain Reboul, Laure Capar, Mathieu Darnet, Benoit Issautier, Stephane Marc, and Alexandre Stopin, (2021), "Characterization of a carbonate geothermal reservoir using rock-physics-guided deep neural networks," The Leading Edge 40: 751–758. - https://doi.org/10.1190/tle40100751.1 BIOGRAPHY Fabien Allo received his BSc in mathematics, physics, and chemistry with a biology option from the Lycée Chateaubriand, Rennes (France) in 2000 and his MSc and engineering degree in geology from the École Nationale Supérieure de Géologie, Nancy (France) in 2003. Since joining CGG 20 years ago, he has held several roles in the UK, Brazil, and now Canada working on inventing, designing, and developing reservoir R&D workflows for seismic forward modeling and inversion with a specific focus on data integration through rock physics. Fabien was recently promoted to the position of rock physics & reservoir expert within CGG's TECH+ Reservoir R&D team. He has increasingly applied geoscience capabilities to energy transition areas, such as carbon capture & sequestration (CCS) and geothermal projects. He received the SEG Award for Best Paper in The Leading Edge in 2021 for a CGG-BRGM co-authored paper published in October 2021: "Characterization of a carbonate geothermal reservoir using rock-physics-guided deep neural networks." (https://www.cgg.com/sites/default/files/2021-10/TLE%20Oct%202021%20Allo%20et%20al%20Final%20published.pdf) CREDITS Seismic Soundoff explores the depth and usefulness of geophysics for the scientific community and the public. If you want to be the first to know about the next episode, please follow or subscribe to the podcast wherever you listen to podcasts. Two of our favorites are Apple Podcasts and"Spotify. If you have episode ideas, feedback for the show, or want to sponsor a future episode, find the "Contact Seismic Soundoff" box at https://seg.org/podcast. Zach Bridges created original music for this show. Andrew Geary hosted, edited, and produced this episode at TreasureMint. The SEG podcast team is Jennifer Cobb, Kathy Gamble, and Ally McGinnis.

Neuroscientist Kalanit Grill-Spector studies the physiology of human vision and says that the ways computers and people see are in some ways similar, but in other ways quite different. In fact, she says, rapid advances in computational modeling, such as deep neural networks, applied to brain data and new imaging technologies, like quantitative MRI and diffusion MRI, are revolutionizing our understanding of how the human brain sees. We're unraveling how the brain “computes” visual information, as Grill-Spector tells host Russ Altman on this episode of Stanford Engineering's The Future of Everything podcast.Chapter Time Stamps:(00:01:30) Episode introduction: Exploring the fascinating field of cognitive neuroscience and brain development with Kalanit Grill-Spector.(00:02:45) Dr Grill-Spector's background and research interests: The intersection of cognitive neuroscience, psychology, and computer science.(00:04:00) The crucial role of experience in shaping brain development: Understanding how environmental factors influence neural specialization.(00:09:55) The development of word processing regions in the brain: Investigating the emergence and evolution of brain regions associated with reading and word recognition.(00:11:30) The evolution of word specialization and its implications: Exploring how the brain acquires the ability to read and process words.(00:14:20) Shift in research focus to studying brain development in infants: Exploring the critical early phases of brain development and the impact of experience on neural circuits.(00:16:40) Pokemon, Brain Representation, and Perception: The surprising findings on the continued development of word and face processing regions. Discovering the extended period of specialization and plasticity in these brain areas.(00:19:10) Unexpected decline in specialization for body parts, particularly hands: Examining the trade-off between different cognitive abilities as brain regions specialize.(00:22:00) Understanding the potential impact of experience on brain organization: Examining how environmental factors shape the neural pathways and cognitive capabilities.(00:25:00) Investigating the influence of Pokemon on brain representation and perception: Analyzing the effects of exposure to specific visual stimuli on brain organization.(00:27:15) The unique characteristics of Pokemon stimuli: Exploring how visual features, animacy, and stimulus size affect brain responses.(00:29:00) Specificity of brain representation for Pokemons: Uncovering whether the brain develops distinct neural pathways for Pokemon stimuli.(00:31:45) Comparing the effects of word learning: Understanding the potential trade-offs in brain specialization.(00:32:45) Technical challenges in studying infant's brains: Discussing the need for new tools and analysis methods to study developing brains.

Vivienne Sze is an associate professor in MIT's Department of Electrical Engineering and Computer Science. She's a coauthor of Efficient Processing of Deep Neural Networks. A full transcript will be available at cap.csail.mit.edu

Dr. Geoffrey Hinton recently retired from Google, saying that he wanted to be able to speak freely about his concerns regarding artificial intelligence without having to consider the impact to his employer. So what is the Godfather of AI worried about? See omnystudio.com/listener for privacy information.

This is a recap of the top 10 posts on Hacker News on April 25th, 2023.(00:36): Smartphones with Qualcomm chip secretly send personal data to QualcommOriginal post: https://news.ycombinator.com/item?id=35698547(01:43): The EU suppressed a 300-page study that found piracy doesn't harm salesOriginal post: https://news.ycombinator.com/item?id=35701785(02:53): Microsoft Edge is leaking the sites you visit to BingOriginal post: https://news.ycombinator.com/item?id=35703789(04:02): Use of antibiotics in farming ‘endangering human immune system'Original post: https://news.ycombinator.com/item?id=35700881(05:17): People who use Notion to plan their whole livesOriginal post: https://news.ycombinator.com/item?id=35698521(06:38): A non-technical explanation of deep learningOriginal post: https://news.ycombinator.com/item?id=35701572(07:47): Shell admits 1.5C climate goal means immediate end to fossil fuel growthOriginal post: https://news.ycombinator.com/item?id=35702201(09:09): Call on the IRS to provide libre tax-filing softwareOriginal post: https://news.ycombinator.com/item?id=35705469(10:36): Deep Neural Networks from Scratch in ZigOriginal post: https://news.ycombinator.com/item?id=35696776(11:54): NitroKey disappoints meOriginal post: https://news.ycombinator.com/item?id=35706858This is a third-party project, independent from HN and YC. Text and audio generated using AI, by wondercraft.ai. Create your own studio quality podcast with text as the only input in seconds at app.wondercraft.ai. Issues or feedback? We'd love to hear from you: team@wondercraft.ai

Link to bioRxiv paper: http://biorxiv.org/cgi/content/short/2023.04.22.537916v1?rss=1 Authors: Lindsey, J. W., Issa, E. B. Abstract: Object classification has been proposed as a principal objective of the primate ventral visual stream. However, optimizing for object classification alone does not constrain how other variables may be encoded in high-level visual representations. Here, we studied how the latent sources of variation in a visual scene are encoded within high-dimensional population codes in primate visual cortex and in deep neural networks (DNNs). In particular, we focused on the degree to which different sources of variation are represented in non-overlapping ("factorized") subspaces of population activity. In the monkey ventral visual hierarchy, we found that factorization of object pose and background information from object identity increased in higher-level regions. To test the importance of factorization in computational models of the brain, we then conducted a detailed large-scale analysis of factorization of individual scene parameters -- lighting, background, camera viewpoint, and object pose -- in a diverse library of DNN models of the visual system. Models which best matched neural, fMRI and behavioral data from both monkeys and humans across 12 datasets tended to be those which factorized scene parameters most strongly. In contrast, invariance to object pose and camera viewpoint in models was negatively associated with a match to neural and behavioral data. Intriguingly, we found that factorization was similar in magnitude and complementary to classification performance as an indicator of the most brainlike models suggesting a new principle. Thus, we propose that factorization of visual scene information is a widely used strategy in brains and DNN models. Copy rights belong to original authors. Visit the link for more info Podcast created by Paper Player, LLC
Link to bioRxiv paper: http://biorxiv.org/cgi/content/short/2023.02.13.528288v1?rss=1 Authors: Suzuki, K., Seth, A. K., Schwartzman, D. J. Abstract: Visual hallucinations (VHs) are perceptions of objects or events in the absence of the sensory stimulation that would normally support such perceptions. Although all VHs share this core characteristic, there are substantial phenomenological differences between VHs that have different aetiologies, such as those arising from neurological conditions, visual loss, or psychedelic compounds. Here, we examine the potential mechanistic basis of these differences by leveraging recent advances in visualising the learned representations of a coupled classifier and generative deep neural network - an approach we call 'computational (neuro)phenomenology'. Examining three aetiologically distinct populations in which VHs occur - neurological conditions (Parkinson's Disease and Lewy Body Dementia), visual loss (Charles Bonnet Syndrome, CBS), and psychedelics - we identify three dimensions relevant to distinguishing these classes of VHs: realism (veridicality), dependence on sensory input (spontaneity), and complexity. By selectively tuning the parameters of the visualisation algorithm to reflect influence along each of these phenomenological dimensions we were able to generate 'synthetic VHs' that were characteristic of the VHs experienced by each aetiology. We verified the validity of this approach experimentally in two studies that examined the phenomenology of VHs in neurological and CBS patients, and in people with recent psychedelic experience. These studies confirmed the existence of phenomenological differences across these three dimensions between groups, and crucially, found that the appropriate synthetic VHs were representative of each group's hallucinatory phenomenology. Together, our findings highlight the phenomenological diversity of VHs associated with distinct causal factors and demonstrate how a neural network model of visual phenomenology can successfully capture the distinctive visual characteristics of hallucinatory experience. Copy rights belong to original authors. Visit the link for more info Podcast created by Paper Player, LLC

Inferring Line-of-Sight Velocities and Doppler Widths from Stokes Profiles of GST NIRIS Using Stacked Deep Neural Networks by Haodi Jiang et al. on Monday 10 October Obtaining high-quality magnetic and velocity fields through Stokes inversion is crucial in solar physics. In this paper, we present a new deep learning method, named Stacked Deep Neural Networks (SDNN), for inferring line-of-sight (LOS) velocities and Doppler widths from Stokes profiles collected by the Near InfraRed Imaging Spectropolarimeter (NIRIS) on the 1.6 m Goode Solar Telescope (GST) at the Big Bear Solar Observatory (BBSO). The training data of SDNN is prepared by a Milne-Eddington (ME) inversion code used by BBSO. We quantitatively assess SDNN, comparing its inversion results with those obtained by the ME inversion code and related machine learning (ML) algorithms such as multiple support vector regression, multilayer perceptrons and a pixel-level convolutional neural network. Major findings from our experimental study are summarized as follows. First, the SDNN-inferred LOS velocities are highly correlated to the ME-calculated ones with the Pearson product-moment correlation coefficient being close to 0.9 on average. Second, SDNN is faster, while producing smoother and cleaner LOS velocity and Doppler width maps, than the ME inversion code. Third, the maps produced by SDNN are closer to ME's maps than those from the related ML algorithms, demonstrating the better learning capability of SDNN than the ML algorithms. Finally, comparison between the inversion results of ME and SDNN based on GST/NIRIS and those from the Helioseismic and Magnetic Imager on board the Solar Dynamics Observatory in flare-prolific active region NOAA 12673 is presented. We also discuss extensions of SDNN for inferring vector magnetic fields with empirical evaluation. arXiv: http://arxiv.org/abs/http://arxiv.org/abs/2210.04122v1
Link to bioRxiv paper: http://biorxiv.org/cgi/content/short/2022.09.08.507097v1?rss=1 Authors: Lee, H., Choi, W., Lee, D., Paik, S.-B. Abstract: The ability to compare quantities of visual objects with two distinct measures, proportion and difference, is observed in newborn animals. Nevertheless, how this function originates in the brain, even before training, remains unknown. Here, we show that neuronal tuning for quantity comparison can arise spontaneously in completely untrained deep neural networks. Using a biologically inspired model neural network, we found that units selective to proportions and differences between visual quantities emerge in randomly initialized networks and that they enable the network to perform quantity comparison tasks. Further analysis shows that two distinct tunings to proportion and difference both originate from a random summation of monotonic, nonlinear responses to changes in relative quantities. Notably, we found that a slight difference in the nonlinearity profile determines the type of measure. Our results suggest that visual quantity comparisons are primitive types of functions that can emerge spontaneously in random feedforward networks. Copy rights belong to original authors. Visit the link for more info Podcast created by PaperPlayer
Link to bioRxiv paper: http://biorxiv.org/cgi/content/short/2022.09.08.507096v1?rss=1 Authors: Cheon, J., Baek, S., Paik, S.-B. Abstract: The ability to perceive visual objects with various types of transformations, such as rotation, translation, and scaling, is crucial for consistent object recognition. In machine learning, invariant object detection for a network is often implemented by augmentation with a massive number of training images, but the mechanism of invariant object detection in biological brains - how invariance arises initially and whether it requires visual experience - remains elusive. Here, using a model neural network of the hierarchical visual pathway of the brain, we show that invariance of object detection can emerge spontaneously in the complete absence of learning. First, we found that units selective to a particular object class arise in randomly initialized networks even before visual training. Intriguingly, these units show robust tuning to images of each object class under a wide range of image transformation types, such as viewpoint rotation. We confirmed that this "innate" invariance of object selectivity enables untrained networks to perform an object-detection task robustly, even with images that have been significantly modulated. Our computational model predicts that invariant object tuning originates from combinations of non-invariant units via random feedforward projections, and we confirmed that the predicted profile of feedforward projections is observed in untrained networks. Our results suggest that invariance of object detection is an innate characteristic that can emerge spontaneously in random feedforward networks. Copy rights belong to original authors. Visit the link for more info Podcast created by PaperPlayer

בפרק זה אירחנו את שקד זיכלינסקי, ראש קבוצת ההמלצות של לייטריקס. שקד ריכז עבורנו את ששת המאמרים החשובים שכל דאטא סיינטיסט מודרני חייב להכיר. ששת המאמרים הם: (1) Attention Is All You Need (2) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (3) A Style-Based Generator Architecture for Generative Adversarial Networks (4) Learning Transferable Visual Models From Natural Language Supervision (5) Mastering the Game of Go with Deep Neural Networks and Tree Search (6) Deep Neural Networks for YouTube Recommendations שקד גם כתב בהרחבה במדיום פה: https://towardsdatascience.com/6-papers-every-modern-data-scientist-must-read-1d0e708becd

This week we are joined by Kyunghyun Cho. He is an associate professor of computer science and data science at New York University, a research scientist at Facebook AI Research and a CIFAR Associate Fellow. On top of this he also co-chaired the recent ICLR 2020 virtual conference.We talk about a variety of topics in this weeks episode including the recent ICLR conference, energy functions, shortcut learning and the roles popularized Deep Learning research areas play in answering the question “What is Intelligence?”.Underrated ML Twitter: https://twitter.com/underrated_mlKyunghyun Cho Twitter: https://twitter.com/kchonyc?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5EauthorPlease let us know who you thought presented the most underrated paper in the form below:https://forms.gle/97MgHvTkXgdB41TC8Links to the papers:“Shortcut Learning in Deep Neural Networks” - https://arxiv.org/pdf/2004.07780.pdf"Bayesian Deep Learning and a Probabilistic Perspective of Generalization” - https://arxiv.org/abs/2002.08791"Classifier-agnostic saliency map extraction" - https://arxiv.org/abs/1805.08249“Deep Energy Estimator Networks” - https://arxiv.org/abs/1805.08306“End-to-End Learning for Structured Prediction Energy Networks” - https://arxiv.org/abs/1703.05667“On approximating nabla f with neural networks” - https://arxiv.org/abs/1910.12744“Adversarial NLI: A New Benchmark for Natural Language Understanding“ - https://arxiv.org/abs/1910.14599“Learning the Difference that Makes a Difference with Counterfactually-Augmented Data” - https://arxiv.org/abs/1909.12434“Learning Concepts with Energy Functions” - https://openai.com/blog/learning-concepts-with-energy-functions/

https://go.dok.community/slack https://dok.community ABSTRACT OF THE TALK When providing data analysis as a service, one must tackle several problems. Data privacy and protection by design are crucial when working on sensitive data. Performance and scalability are fundamental for compute-intensive workloads, e.g. training Deep Neural Networks. User-friendly interfaces and fast prototyping tools are essential to allow domain experts to experiment with new techniques. Portability and reproducibility are necessary to assess the actual value of results. Kubernetes is the best platform to provide reliable, elastic, and maintainable services. However, Kubernetes alone is not enough to achieve large-scale multi-tenant reproducible data analysis. OOTB support for multi-tenancy is too rough, with only two levels of segregation (i.e. the single namespace or the entire cluster). Offloading computation to off-cluster resources is non-trivial and requires the user's manual configuration. Also, Jupyter Notebooks per se cannot provide much scalability (they execute locally and sequentially) and reproducibility (users can run cells in any order and any number of times). The Dossier platform allows system administrators to manage multi-tenant distributed Jupyter Notebooks at the cluster level in the Kubernetes way, i.e. through CRDs. Namespaces are aggregated in Tenants, and all security and accountability aspects are managed at that level. Each Notebook spawns into a user-dedicated namespace, subject to all Tenant-level constraints. Users can rely on provisioned resources, either in-cluster worker nodes or external resources like HPC facilities. Plus, they can plug their computing nodes in a BYOD fashion. Notebooks are interpreted as distributed workflows, where each cell is a task that one can offload to a different location in charge of its execution. BIO Iacopo Colonnelli is a Computer Science research fellow. He received his Ph.D. with honours in Modeling and Data Science at Università di Torino with a thesis on novel workflow models for heterogeneous distributed systems, and his master's degree in Computer Engineering from Politecnico di Torino with a thesis on a high-performance parallel tracking algorithm for the ALICE experiment at CERN. His research focuses on both statistical and computational aspects of data analysis at large scale and on workflow modeling and management in heterogeneous distributed architectures. Dario is an SWE that turned DevOps, and he's regretting this choice day by day. Besides making memes on Twitter that gain more reactions than technical discussions, leading the development of Open Source projects at CLASTIX, an Open Source-based start-up focusing on Multi-Tenancy in Kubernetes. KEY TAKE-AWAYS FROM THE TALK From this talk, people will learn: - The different requirements of Data analysis as a service - How to configure for multi-tenancy at the cluster level with Capsule - How to write distributed workflows as Notebooks with Jupyter Workflows - How to combine all these aspects into a single platform: Dossier All the software presented in the talk is OpenSource, so attendees can directly play with them and include them in their experiments with no additional restrictions.
Are large language models really sentient or conscious? What is explainability (XAI) and how can we create human-aware AI systems for collaborative tasks? Dr. Subbarao Kambhampati sheds some light on these topics, generating explanations for human-in-loop AI systems and understanding 'intelligence' in context to AI systems. He is a Prof of Computer Science at Arizona State University and director of the Yochan lab at ASU where his research focuses on decision-making and planning specifically in the context of human-aware AI systems. He has received multiple awards for his research contributions. He has also been named a fellow of AAAI, AAAS, and ACM and also a distinguished alumnus from the University of Maryland and also recently IIT Madras.Time stamps of conversations:00:00:40 Introduction00:01:32 What got you interested in AI?00:07:40 Definition of intelligence that is not related to human intelligence00:13:40 Sentience vs intelligence in modern AI systems00:24:06 Human aware AI systems for better collaboration00:31:25 Modern AI becoming natural science instead of an engineering task00:37:35 Understanding symbolic concepts to generate accurate explanations00:56:45 Need for explainability and where01:13:00 What motivates you for research, the application associated or theoretical pursuit?01:18:47 Research in academia vs industry01:24:38 DALL-E performance and critiques01:45:40 What makes for a good research thesis? 01:59:06 Different trajectories of a good CS PhD student02:03:42 Focusing on measures vs metrics 02:15:23 Advice to students on getting started with AIArticles referred in the conversationAI as Natural Science?: https://cacm.acm.org/blogs/blog-cacm/261732-ai-as-an-ersatz-natural-science/fulltextPolanyi's Revenge and AI's New Romance with Tacit Knowledge: https://cacm.acm.org/magazines/2021/2/250077-polanyis-revenge-and-ais-new-romance-with-tacit-knowledge/fulltextMore about Prof. RaoHomepage: https://rakaposhi.eas.asu.edu/Twitter: https://twitter.com/rao2zAbout the Host:Jay is a PhD student at Arizona State University.Linkedin: https://www.linkedin.com/in/shahjay22/Twitter: https://twitter.com/jaygshah22Homepage: https://www.public.asu.edu/~jgshah1/ for any queries.Stay tuned for upcoming webinars!***Disclaimer: The information contained in this video represents the views and opinions of the speaker and does not necessarily represent the views or opinions of any institution. It does not constitute an endorsement by any Institution or its affiliates of such video content.***
Have a listen to the first ever Underrated ML podcast! We'll walk you through two papers which we found really interesting followed by a few questions and then finally finishing with our verdict on what we believe was the most underrated paper!Links to the papers can be found below.Critical Learning Periods in Deep Neural Networks - https://arxiv.org/abs/1711.08856A scalable pipeline for designing reconfigurable organisms - https://www.pnas.org/content/117/4/1853

David and Randy explore deep neural networks in Julia using Flux.jl by recreating Grant Sanderson's model for predicting handwritten digits in the MNIST data set. We also show how to visualize model results and training performance in TensorBoard using the TensorBoardLogging.jl package.

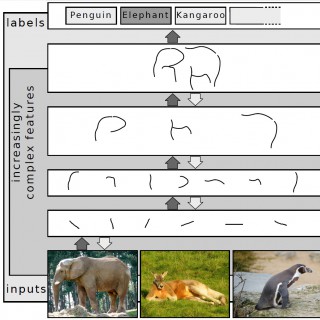
In this episode Dr Peter Bandettini and co-host Dr Brendan Ritchie interview Dr Grace Lindsay. They find out about her new book 'Models of the mind' and about the process of writing a book. In doing so, they consider different types of brain models, from simply descriptive to more mechanistic, from too simple to overfitted. They describe the challenge in neuroscience of network modelling - the many unknowns and limited data and how output of the model may help inform its accuracy. They then discuss specific models, such as Deep Neural Networks, and how this type of modelling may progress in the future. Last, Lindsay gives some thoughts about the future hopes, philosophies, and strategies of modelling - how doing it well is both an art and a science.

Welcome to The Nonlinear Library, where we use Text-to-Speech software to convert the best writing from the Rationalist and EA communities into audio. This is: Opinions on Interpretable Machine Learning and 70 Summaries of Recent Papers, published by lifelonglearner, Peter Hase on the AI Alignment Forum. Crossposted from the AI Alignment Forum. May contain more technical jargon than usual. Peter Hase. UNC Chapel Hill. Owen Shen. UC San Diego. With thanks to Robert Kirk and Mohit Bansal for helpful feedback on this post. Introduction. Model interpretability was a bullet point in Concrete Problems in AI Safety (2016). Since then, interpretability has come to comprise entire research directions in technical safety agendas (2020); model transparency appears throughout An overview of 11 proposals for building safe advanced AI (2020); and explainable AI has a Twitter hashtag, #XAI. (For more on how interpretability is relevant to AI safety, see here or here.) Interpretability is now a very popular area of research. The interpretability area was the most popular in terms of video views at ACL last year. Model interpretability is now so mainstream there are books on the topic and corporate services promising it. So what's the state of research on this topic? What does progress in interpretability look like, and are we making progress? What is this post? This post summarizes 70 recent papers on model transparency, interpretability, and explainability, limited to a non-random subset of papers from the past 3 years or so. We also give opinions on several active areas of research, and collate another 90 papers that are not summarized. How to read this post. If you want to see high-level opinions on several areas of interpretability research, just read the opinion section, which is organized according to our very ad-hoc set of topic areas. If you want to learn more about what work looks like in a particular area, you can read the summaries of papers in that area. For a quick glance at each area, we highlight one standout paper per area, so you can just check out that summary. If you want to see more work that has come out in an area, look at the non-summarized papers at the end of the post (organized with the same areas as the summarized papers). We assume readers are familiar with basic aspects of interpretability research, i.e. the kinds of concepts in The Mythos of Model Interpretability and Towards A Rigorous Science of Interpretable Machine Learning. We recommend looking at either of these papers if you want a primer on interpretability. We also assume that readers are familiar with older, foundational works like "Why Should I Trust You?: Explaining the Predictions of Any Classifier." Disclaimer: This post is written by a team of two people, and hence its breadth is limited and its content biased by our interests and backgrounds. A few of the summarized papers are our own. Please let us know if you think we've missed anything important that could improve the post. Master List of Summarized Papers. Theory and Opinion. Explanation in Artificial Intelligence: Insights from the Social Sciences. Chris Olah's views on AGI safety. Towards Faithfully Interpretable NLP Systems: How Should We Define and Evaluate Faithfulness? The elephant in the interpretability room: Why use attention as explanation when we have saliency methods? Aligning Faithful Interpretations with their Social Attribution. Evaluation. Are Visual Explanations Useful? A Case Study in Model-in-the-Loop Prediction. Comparing Automatic and Human Evaluation of Local Explanations for Text Classification. Do explanations make VQA models more predictable to a human? Sanity Checks for Saliency Maps. A Benchmark for Interpretability Methods in Deep Neural Networks. Evaluating Explainable AI: Which Algorithmic Explanations Help Users Predict Model Behavior? ERASER: A Benchmark to Evaluate Rationalized NLP Models. On quantitative aspects of model interpretability. Manipulating and M...

Welcome to The Nonlinear Library, where we use Text-to-Speech software to convert the best writing from the Rationalist and EA communities into audio. This is: Opinions on Interpretable Machine Learning and 70 Summaries of Recent Papers, published by lifelonglearner, Peter Hase on the AI Alignment Forum. Peter Hase. UNC Chapel Hill. Owen Shen. UC San Diego. With thanks to Robert Kirk and Mohit Bansal for helpful feedback on this post. Introduction. Model interpretability was a bullet point in Concrete Problems in AI Safety (2016). Since then, interpretability has come to comprise entire research directions in technical safety agendas (2020); model transparency appears throughout An overview of 11 proposals for building safe advanced AI (2020); and explainable AI has a Twitter hashtag, #XAI. (For more on how interpretability is relevant to AI safety, see here or here.) Interpretability is now a very popular area of research. The interpretability area was the most popular in terms of video views at ACL last year. Model interpretability is now so mainstream there are books on the topic and corporate services promising it. So what's the state of research on this topic? What does progress in interpretability look like, and are we making progress? What is this post? This post summarizes 70 recent papers on model transparency, interpretability, and explainability, limited to a non-random subset of papers from the past 3 years or so. We also give opinions on several active areas of research, and collate another 90 papers that are not summarized. How to read this post. If you want to see high-level opinions on several areas of interpretability research, just read the opinion section, which is organized according to our very ad-hoc set of topic areas. If you want to learn more about what work looks like in a particular area, you can read the summaries of papers in that area. For a quick glance at each area, we highlight one standout paper per area, so you can just check out that summary. If you want to see more work that has come out in an area, look at the non-summarized papers at the end of the post (organized with the same areas as the summarized papers). We assume readers are familiar with basic aspects of interpretability research, i.e. the kinds of concepts in The Mythos of Model Interpretability and Towards A Rigorous Science of Interpretable Machine Learning. We recommend looking at either of these papers if you want a primer on interpretability. We also assume that readers are familiar with older, foundational works like "Why Should I Trust You?: Explaining the Predictions of Any Classifier." Disclaimer: This post is written by a team of two people, and hence its breadth is limited and its content biased by our interests and backgrounds. A few of the summarized papers are our own. Please let us know if you think we've missed anything important that could improve the post. Master List of Summarized Papers. Theory and Opinion. Explanation in Artificial Intelligence: Insights from the Social Sciences. Chris Olah's views on AGI safety. Towards Faithfully Interpretable NLP Systems: How Should We Define and Evaluate Faithfulness? The elephant in the interpretability room: Why use attention as explanation when we have saliency methods? Aligning Faithful Interpretations with their Social Attribution. Evaluation. Are Visual Explanations Useful? A Case Study in Model-in-the-Loop Prediction. Comparing Automatic and Human Evaluation of Local Explanations for Text Classification. Do explanations make VQA models more predictable to a human? Sanity Checks for Saliency Maps. A Benchmark for Interpretability Methods in Deep Neural Networks. Evaluating Explainable AI: Which Algorithmic Explanations Help Users Predict Model Behavior? ERASER: A Benchmark to Evaluate Rationalized NLP Models. On quantitative aspects of model interpretability. Manipulating and Measuring Model Interpretability. Methods. Estimating Feature Importance. Neuron Shapley...

When engineers train deep learning models, they are very much “flying blind”. Commonly used approaches for realtime training diagnostics, such as monitoring the train/test loss, are limited. Assessing a network's training process solely through these performance indicators is akin to debugging software without access to internal states through a debugger. To address this, we present COCKPIT, a collection of instruments that enable a closer look into the inner workings of a learning machine, and a more informative and meaningful status report for practitioners. It facilitates the identification of learning phases and failure modes, like ill chosen hyper parameters. 2021: Frank Schneider, Felix Dangel, Philipp Hennig https://arxiv.org/pdf/2102.06604v2.pdf

Cyberpolitik #1: France’s Influence Operations Doctrine— Prateek WaghreIn October, France announced a new doctrine for Information Warfare. This development has received surprisingly little attention in English-language discourse over the last three weeks. It was initially reported by Francesco Busseletti, who highlighted: Objective: to counter the growing spread of fake news and disinformation, aimed at weakening the image of Paris and weakening its armed forces, especially abroad such as the Sahel. Considering that its adversaries no longer hesitate to use the weapon of social media against its military operations, France intends to “win the war before the war”. Its strategy boils down to “being on the offensive” …The Defence Minister Florence Parly’s speech also highlighted this aspect of the “war before the war”. Here’s an excerpt from a google-translated version of her speech.“When used wisely, the weapon of information allows you to win without fighting.”What does the doctrine say?The doctrine identifies six characteristics of the “informational layer of cyberspace”:Contraction of space and time.Ability to conceal/falsify origin due to anonymity.Difficulty with erasing information since it can be duplicated, moved, and re-used without the original context.Any individual can produce and broadcast information. (The minister’s speech seems to have gone as far as stating these individual and anonymous actors are at par with media organisations)The point is that social networks have an equalizing power: on Twitter, the voice of an anonymous user counts as much as that of a major media whose essential function is to inform (sic).Continuous innovation such as deepfakes, AI, AR/VR, etc.The presence of operators who impose their own regulations. A challenge for law enforcement as the space is ‘dematerialised.It defines two types of actors that threaten armed forces:Noting that information war is already an everyday reality for the military, it goes on to say that ‘mastery’ in the information field is now a pre-condition for ‘operational superiority’. And that cyberspace offers opportunities to create effects in ‘both information and physical environments’. The document is peppered with many important statements about Lutte Informatique D’influence (L2I).Definition:military operations conducted in the informational layer of cyberspace to detect, characterize and counter attacks, support StratCom, provide information or (perform) deception, independently or in combination with other operations.L2I stands at “the confluence of cyber defence and influence”. And that it requires skills in common with LID (defensive cyber operations) and LIO (offensive cyber operations).L2I offers opportunities for ‘intelligence gathering’ and ‘deception' operations’. (The minister’s speech defined some boundaries explicitly)the French armies will not conduct an information operation (within) the national territory. The French armies … will not destabilize a foreign state through information actions that would target, for example, its electoral processes.As future challenges, the doctrine identifies the need to build skills and tools, as well as cooperation with firms that specialise in the field and coalitions with allies to coordinate responses.Operationally, this would fall within the purview of the Chief of Staff of the armed forces, who would further rely on the Cyber Defense Commander (COMCYBER) and specialised military units.Two more questionsFor France to come out and explicitly state its doctrine is undoubtedly a significant step. But this also raises two broader questions.What should other democracies do?What will DCN operators do?Camille Francois rightly points out that it raises the question of what democracies can/should do in this space and the possibility of gaining a better understanding of techniques used by countries not named - Russia, China, or Iran.Thomas Rid, in his book Active Measures, argues that liberal democracies cannot be good at disinformation. “For liberal democracies in particular, disinformation represents a double threat: being at the receiving end of active measures will undermine democratic institutions—and giving in to the temptation to design and deploy them will have the same result. It is impossible to excel at disinformation and at democracy at the same time. The stronger and the more robust a democratic body politic, the more resistant to disinformation it will be—and the more reluctant to deploy and optimize disinformation. Weakened democracies, in turn, succumb more easily to the temptations of active measures.”Then, there’s the question of Digital Communication Networks which have become the battlefield for such operations. As Lukasz Olenik notes in his overview of the French doctrine, Facebook has taken action against Coordinated Inauthentic Behaviour it identified originating from a network with links to the French Military in December 2020:We found this activity as part of our internal investigation into suspected coordinated inauthentic behavior in Francophone Africa. Although the people behind it attempted to conceal their identities and coordination, our investigation found links to individuals associated with French military.Now that France has explicitly stated its doctrine (and maybe others will follow), will platforms act more aggressively, considering they are already under fire for either enabling or not doing enough to mitigate the fallout from influence operations? Or, will there be wink-wink-nudge-nudge arrangements between them and a particular set of states?Note: Google Translate was used for French to English translations.If you enjoy this newsletter please consider taking our 12 week Graduate Certificate Programmes in Technology & Policy, Public Policy, Defence & Foreign Affairs and Health & Life Sciences. Click here to apply and know more. You can also get a gift coupon worth ₹1000 every time you successfully refer a friend to our programmes.Siliconpolitik #1: AI Chips — Arjun GargeyasWhat are They?One of the emerging applications of semiconductor devices is the concept of Artificial Intelligence (AI) chips. With new and emerging technologies cropping up, there is an increased need for chipsets with increasing computational power and capabilities. Technologies like Machine Learning and Deep Neural Networks, which are part of the AI ecosystem, have a tremendous workload that cannot be fulfilled by traditional chipsets. AI algorithms work on parallel processing or parallelism, which is the ability to multitask and simultaneously run different computational processes. AI chips, in recent years, have tried to incorporate the needs of AI algorithms into chipsets that can be used both in the cloud as well as at network edges (in smartphones, tablets, and other consumer devices).The diverse applications of AI chips have increased its role in the global economy with companies from various industries all looking to maximise the benefits of AI chip technology. Robotics and autonomous driving, for example, need AI algorithms for efficient and effective working, with the computational power of the chipsets needing incredibly fast processing speeds. This has evolved the role of chipsets with AI capabilities from only being used in the cloud or servers to being used in consumer products at the network edges. However, applications such as Biometrics and Image Recognition need AI chips in the cloud or servers for maintaining a large amount of data. The use of AI chips remains integral in data centers which eventually reduces operational costs and improves information management. Why They MatterThe market for AI chips has consistently increased in the last decade with AI chipsets projected to account for 22% of the global AI revenue by 2022. A strong compounded annual growth rate of 54% has been projected for the AI chips market with technologically advanced regions like the Americas and Europe dominating the market in the future. AI chips also rely on a variety of companies, ranging from smartphone manufacturers like Apple, Samsung, and Huawei, to traditional chip designers like Qualcomm and MediaTek, to intellectual property (IP) license providers like ARM. With most of the major semiconductor companies across the world in the business, AI chips look to be the next big thing for the industry. Semiconductor companies have already thrown their hats in the AI ring with the development of advanced AI chips like Graphical Processing Units (GPUs). NVIDIA has a dedicated application programming language called CUDA used in parallel computing on GPUs. Other targeted AI chips like Field Programmable Gate Arrays (FPGAs) and Application Specific Integrated Circuits (ASICs) are developed for specific applications of AI technology. Companies like Microsoft and Google have also invested in the manufacture of these chipsets keeping in mind specific needs such as the speech processing unit of Google Assistant.With increasing global economic revenue and a large market ripe for capture, the presence of China in the AI chips has also been increasing. AI chip funding activity in China has been driven by the hope of creating industry-leading capabilities in machine learning, deep compression, pruning, and system-level optimization for neural networks. Chinese technology companies like Alibaba and Huawei have invested heavily in the manufacture of AI chips for smartphones and other devices. Some Bitcoin mining equipment manufacturers are also getting into the AI optimization game. With domestic AI research in China still playing catch up to the capabilities of Western countries like the United States, these local manufacturing companies have relied on tweaking existing algorithms to create modified AI models. But increased investments along with state support and financing, similar to the semiconductor industry in China, has made AI chips an important technology worth pursuing in technologically adept states. The race for the domination of the global AI chips markets is something to watch out for in the very near future. Cyberpolitik #2: Are Norms Possible?— Sapni G KSince the last edition of this newsletter, much has happened on cyberspace and international action for establishing norms for its operation and regulation. The United States of America joined the Paris Call for Trust and Security in the cyberspace. The 2018 Call led by the French, proposes a multi-stakeholder model for laying down norms for activity in cyberspace during peacetime. This includes, but is not limited to cybersecurity and the concerns of systemic harms to individuals and critical infrastructure. The Call details nine principles that are open for states, local governments, companies, and civil society organizations to support. Protect individuals and infrastructureProtect the internet Defend electoral processes Defend intellectual propertyNon-proliferation Lifecycle security Cyber hygiene No private hack back International norms They incorporate norms of international law, including the ideas put forth by the UDHR, customary international law, and state laws on the governance of information and communication technologies. This operates as a non-binding, non-enforceable set of principles that are to guide the supporters of the Call and their actions. Most major US tech companies including Microsoft, Google, Facebook Inc (now Meta) are already supporters of the Call and have engaged closely with the various associated working groups. However, the US officially supporting the Call signals that it is no longer holding back in international norm-setting in cyberspace. This could also be read as a furtherance of the USA’s reinvigorated interest in cyber norms, both in peacetime and military applications, as evidenced by recent documents such as the 2021 Interim National Security Strategic Guidance and the recent report by the Department of Defense. However, it is noteworthy that the US has not yet made any concrete steps to sign up to the Global Commission on the Stability of Cyberspace, an effort led by research institutes in the Netherlands and Singapore with the support of the French, Dutch, and Singapore governments, which is also engaged in drawing out international norms for cyberspace during peacetime and armed conflict. China, Russia, Israel, and Iran are other major actors in cyberspace that have not supported the call yet. This is indicative of the fissures in international norm-setting on cyberspace, particularly when China is marching ahead creating a regulatory environment that can have ripple effects internationally. India has not officially supported the Call, but several Indian enterprises and the Karnataka Centre of Excellence of Cybersecurity have joined the Call. It is a proposal worth consideration for the Indian government. An early head start can give India a definitive say in the development of doctrines as well as import legislative principles that can be beneficial to the many millions of Indians who go online every day. Siliconpolitik #2: US-China-Chips — It’s Complicated— Pranay KotasthaneThree recent news reports have turned the world's attention back to the links between the US and China in the semiconductor domain. Until now, the commonplace understanding is that the US is focused on constraining China's progress in the semiconductor domain, a weak link in China's otherwise impressive technology stack. These news reports contest this narrative by suggesting the constraints don't seem to be working, as many US investors and firms are still flocking to China.WSJ reports that between 2017 and 2020, many US companies, including Intel, have invested in Chinese design companies. The number of deals (58) has more than doubled when compared to the 2013-2016 period.Bloomberg reports Intel wanted to start a manufacturing plant in Chengdu, but the White House officials discouraged it.These reports come on the heels of another big claim in mid-October, when Alibaba unveiled a 5nm server chip, making many heads turn. This news seemed to indicate that China's pursuit of semiconductor self-sufficiency is bearing fruit despite the geopolitical headwinds.Connecting the DotsIntel seems to be interested in China a lot. While the WSJ report showed that Intel is among the active investors in a Chinese Electronic Design Automation (EDA) firm, the Bloomberg report points out that Intel also wants to build a fab in Chengdu. It’s notable that both these stages of the semiconductor value chain are precisely where the US had planned to restrict Chinese access during the Trump administration. Reportedly, the US NSA Jake Sullivan and a few senators, want to change the investment screening methods to prevent such deals in the future.Why are US companies still rushing to China?The supply side: The Chinese government's incentives are 'crowding in' investments from Chinese firms and global semiconductor players alike.The demand side: A significant number of customers of chip makers are based in China - laptop manufacturers, phone manufacturers, servers etc. Companies still want a piece of that pie because homegrown alternatives in China are not enough, yet. It's a mouth-watering market, still.My initial assessmentThe number of investment deals between 2017-20 (58) doesn't sound that big in the overall scheme of things. They also mostly appear to be in chip design firms. What this does suggest is like many industrial policies, there is a crowding-in of capital. When a player the size of the Chinese government throws big money at a problem (starting the Chip Fund in 2014), this is expected to happen. There will be national champions and duds, both. The question really is, how long such subsidies can be sustained.The time period 2017-2020 suggests that the US companies rushed into China before the Trump administration tightened the export controls.Intel's investment in a Chinese EDA firm and a possible fab is indeed worrying. Although, the tone of the Chengdu fab proposal suggests it is more a tactic to get the CHIPS Act passed in the US, which will guarantee big subsidies for the likes of Intel back home. The report had no numbers, or plans, just a few unnamed sources.The demand side question is an important one. As long as China remains the hub for electronics Original Equipment Manufacturers (OEMs), chip makers will find it attractive to sell their products to China. Solving this will require a plurilateral effort to move electronics manufacturing -- and not leading-edge chip manufacturing alone -- out of China.Finally, the Alibaba server chip news report has many unknowns. Unveiling a chip is different from being able to produce it. Manufacturing at 5nm is not possible in China. They must rely on TSMC (and now Samsung) for this purpose. Moreover, the processor IP is still ARM, something that Alibaba hasn't been able to displace.The reportage of the kind WSJ, Bloomberg is putting out is indicative of the change in mindset in the US. A few years ago, no one would have even cared about such investments. These are front-page news items now.I expect some more export controls and more subsidies from the US government, both.Our Reading Menu1. [Full Text] of the Paris Call for Trust and Security in the cyberspace2. [Full Text] 2021 Interim National Security Strategic Guidance of the White house 3. [Policy Study] Principles for Content Policy and Governance by Chris Riley, R Street 4. [Article] by Oleg Shakirov discussing the US-Russia rapprochement on Information and Cyber Security5. [Blog] by Oleg Shakirov explaining why US-Russia cooperation on countering Ransomware threats makes sense This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit hightechir.substack.com
Nick talks to neuroscientist and writer Dr. Erik Hoel. Erik is a professor of biology at Tufts University. He received his PhD in neuroscience from the University of Wisconsin, where he studied under the sleep and consciousness researcher, Giulio Tononi. He did postdoctoral work at Columbia University, where he used information theory and other analytical tools to explore the biological basis of consciousness. He has come up with the so-called Overfitted Brain Hypothesis of dreaming, which explains the potential adaptive function of dreams by drawing analogies to techniques used to train Deep Neural Networks in the world of machine learning. Erik and Nick discuss the biology and phenomenology of dreams and sleep generally, including some of the various theories for why we sleep. They also discuss Deep Learning (on a very basic level) and Erik described the Overfitted Brain Hypothesis of dreaming. They also discuss fiction and the arts, including Erik's new novel and the potential evolutionary reasons for why humans create and consume fiction, as well as some technology-driven developments that are reshaping how we create and consume written work online. USEFUL LINKS:Download the podcast & follow Nick at his website[https://www.nickjikomes.com]Support the show on Patreon & get early access to episodes[https://www.patreon.com/nickjikomes]Sign up for the weekly Mind & Matter newsletter[https://mindandmatter.substack.com/]Athletic Greens, comprehensive daily nutrition (Free 1-year supply of Vitamin D w/ purchase)[https://www.athleticgreens.com/mindandmatter]Try MUD/WTR, a mushroom-based coffee alternative[https://www.mudwtr.com/mindmatter]Discount Code ($5 off) = MINDMATTEROrganize your digital highlights & notes w/ Readwise (2 months free w/ subscription)[https://readwise.io/nickjikomes/]Start your own podcast (get $20 Amazon gift card after signup)[https://www.buzzsprout.com/?referrer_id=1507198]Buy Mind & Matter T-Shirts[https://www.etsy.com/shop/OURMIND?ref=simple-shop-header-name&listing_id=1036758072§ion_id=34648633]Connect with Nick Jikomes on Twitter[https://twitter.com/trikomes]Learn more about our podcast sponsor, Dosist[https://dosist.com/]ABOUT Nick Jikomes:Nick is a neuroscientist and podcast host. He is currently Director of Science & Innovation at Leafly, a technology startup in the legal cannabis industry. He received a Ph.D. in Neuroscience from Harvard University and a B.S. in Genetics from the University of Wisconsin-Madison.Support the show (https://www.patreon.com/nickjikomes)

In this episode of Intel on AI host Amir Khosrowshahi and Melanie Mitchell talk about the paradox of studying human intelligence and the limitations of deep neural networks. Melanie is the Davis Professor of Complexity at the Santa Fe Institute, former professor of Computer Science at Portland State University, and the author/editor of six books and numerous scholarly papers in the fields of artificial intelligence, cognitive science, and complex systems, including Complexity: A Guided Tour and Artificial Intelligence: A Guide for Thinking Humans. In the episode, Melanie and Amir discuss how intelligence emerges from the substrate of neurons and why being able to perceive abstract similarities between different situations via analogies is at the core of cognition. Melanie goes into detail about deep neural networks using spurious statistical correlations, the distinction between generative and discriminative systems and machine learning, and the theory that a fundamental part of the human brain is trying to predict what is going to happen next based on prior experience. She also talks about creating the Copycat software, the dangers of artificial intelligence (AI) being easy to manipulate even in very narrow areas, and the importance of getting inspiration from biological intelligence. Academic research discussed in the podcast episode: Gödel, Escher, Bach: an Eternal Golden Braid Fluid Concepts and Creative Analogies: Computer Models Of The Fundamental Mechanisms Of Thought A computational model for solving problems from the Raven's Progressive Matrices intelligence test using iconic visual representations A Framework for Representing Knowledge On the Measure of Intelligence The Abstraction and Reasoning Corpus (ARC) Human-level concept learning through probabilistic program induction Why AI is Harder Than We Think We Shouldn't be Scared by ‘Superintelligent A.I.' (New York Times opinion piece)

In episode two I am joined by Even Oldridge, Senior Manager at NVIDIA, who is leading the Merlin Team. These people are working on an open-source framework for building large-scale deep learning recommender systems and have already won numerous RecSys competitions.We talk about the relevance and impact of deep learning applied to recommender systems as well as the challenges and pitfalls of deep learning based recommender systems. We briefly touch on Even's early data science contributions at PlentyOfFish, a Canadian online-dating platform. Starting with personalized recommendations of people to people he transitioned to realtor, a real-estate marketplace. From the potentially biggest social decision in life to the probably biggest financial decision in life he has really been involved with recommender systems at the extremes. At NVIDIA - to which he refers as the one company that works with all the other AI companies - he pushes for Merlin as large-scale, accessible and efficient platform for developing and deploying recommender systems on GPUs.This brought him also closer to the community which he served as industry Co-Chair at RecSys in 2021 as well as to winning multiple RecSys competitions with his team in the recent years.Enjoy this enriching episode of RECSPERTS - Recommender Systems Experts.Links from this Episode: Even Oldridge on LinkedIn and Twitter NVIDIA Merlin NVIDIA Merlin at GitHub Even's upcoming Talk at GTC 2021: Building and Deploying Recommender Systems Quickly and Easily with NVIDIA Merlin PlentyOfFish, realtor fast.ai Twitter RecSys Challenge 2021 Recommending music on Spotify with Deep Learning Papers Dacrema et al. (2019): Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches (best paper award at RecSys 2019) Jannach et al. (2020): Why Are Deep Learning Models Not Consistently Winning Recommender Systems Competitions Yet?: A Position Paper Moreira et al. (2021): Transformers4Rec: Bridging the Gap between NLP and Sequential / Session-Based Recommendation Deotte et al. (2021): GPU Accelerated Boosted Trees and Deep Neural Networks for Better Recommender Systems General Links: Follow me on Twitter: https://twitter.com/LivesInAnalogia Send me your comments, questions and suggestions to marcel@recsperts.com Podcast Website: https://www.recsperts.com/
Do Vision Transformers work in the same way as CNNs? Do the internal representational structures of ViTs and CNNs differ? An in-depth analysis article: https://arxiv.org/pdf/2108.08810.pdfListen to the full conversation here: https://youtu.be/htnJxcwJqeADr. Maithra Raghu is a senior research scientist at Google working on analyzing the internal workings of deep neural networks so that we can deploy them better keeping humans in the loop. She recently graduated from Cornell University with a Ph.D. in CS and previously graduated from Cambridge University with BA and Masters in Mathematics. She has received multiple awards for her research work including the Forbes 30 under 30.Maithra's Homepage: https://maithraraghu.comAbout the Host:Jay is a Ph.D. student at Arizona State University, doing research on building Interpretable AI models for Medical Diagnosis.Jay Shah: https://www.linkedin.com/in/shahjay22/You can reach out to https://www.public.asu.edu/~jgshah1/ for any queries.Stay tuned for upcoming webinars!#explainableai #reliableai #robustai #machinelearning***Disclaimer: The information contained in this video represents the views and opinions of the speaker and does not necessarily represent the views or opinions of any institution. It does not constitute an endorsement by any Institution or its affiliates of such video content.***
This Week in Machine Learning & Artificial Intelligence (AI) Podcast
Today we're joined by Andrea Banino, a research scientist at DeepMind. In our conversation with Andrea, we explore his interest in artificial general intelligence by way of episodic memory, the relationship between memory and intelligence, the challenges of applying memory in the context of neural networks, and how to overcome problems of generalization. We also discuss his work on the PonderNet, a neural network that “budgets” its computational investment in solving a problem, according to the inherent complexity of the problem, the impetus and goals of this research, and how PonderNet connects to his memory research. The complete show notes for this episode can be found at twimlai.com/go/528.
Dr. Maithra Raghu is a senior research scientist at Google working on analyzing the internal workings of deep neural networks so that we can deploy them better keeping humans in the loop. She recently graduated from Cornell University with a PhD in CS and previously graduated from Cambridge University with BA and Masters in Mathematics. She has received multiple awards for her research work including the Forbes 30 under 30.Questions that we cover00:00:00 Introductions00:01:00 To understand more about your research interests, can you tell us what kind of research questions you are interested in while working at Google Brain?00:04:45 What interested you about it and how did you get started?00:15:00 What is one thing that surprises/puzzles you about deep learning effectiveness to date?00:22:05 What's the difference between being a researcher in academia/PhD student vs being a researcher at a big organization (Google)?00:28:35 In what use cases do you think ViTs might be a good choice to perform image analysis over CNN vs where do you think CNNs still have an undoubted advantage?00:37:15 Why does ViT perform better than ResNet only on larger datasets and not on mid-sized datasets or smaller? 00:43:55 In regards to medical imaging tasks, would it be theoretically wrong to pre-train the model on dataset A and fine-tune it on dataset B?00:47:35 Do you think ViT or transformer-based models already have/have the potential to cause a paradigm shift in the way we approach imaging tasks? Why?00:5:25 Medical datasets are often limited in size, what are your views on tackling these problems in the near future00:55:55 From an internal representation perspective, do you think deep neural networks can have the ability of reasoning?00:58:20 How did you decide on your own PhD research topic? Advice you would give to graduate researchers trying to find a research problem for their thesis?01:04:00 Many times researchers/students feel stuck/overwhelmed with a particular project they are working on, how do you suggest based on experience to tackling that?01:10:35 How do you now/as a graduate student used to keep up with the latest research in ML/DL?Maithra's Homepage: https://maithraraghu.comBlogpost talked about: https://maithraraghu.com/blog/2020/Reflections_on_my_Machine_Learning_PhD_Journey/Her Twitter: https://twitter.com/maithra_raghuAbout the Host:Jay is a PhD student at Arizona State University, doing research on building Interpretable AI models for Medical Diagnosis.Jay Shah: https://www.linkedin.com/in/shahjay22/You can reach out to https://www.public.asu.edu/~jgshah1/ for any queries.Stay tuned for upcoming webinars!#explainableai #reliableai #robustai #machinelearning***Disclaimer: The information contained in this video represents the views and opinions of the speaker and does not necessarily represent the views or opinions of any institution. It does not constitute an endorsement by any Institution or its affiliates of such video content.***

Dr. Jianfeng Gao is a veteran computer scientist, an IEEE Fellow and the current head of the Deep Learning Group at Microsoft Research. He and his team are exploring novel approaches to advancing the state-of-the-art on deep learning in areas like NLP, computer vision, multi-modal intelligence and conversational AI. Today, Dr. Gao gives us an overview of the deep learning landscape and talks about his latest work on Multi-task Deep Neural Networks, Unified Language Modeling and vision-language pre-training. He also unpacks the science behind task-oriented dialog systems as well as social chatbots like Microsoft Xiaoice, and gives us some great book recommendations along the way! https://www.microsoft.com/research
Dr. Jianfeng Gao is a veteran computer scientist, an IEEE Fellow and the current head of the Deep Learning Group at Microsoft Research. He and his team are exploring novel approaches to advancing the state-of-the-art on deep learning in areas like NLP, computer vision, multi-modal intelligence and conversational AI. Today, Dr. Gao gives us an overview of the deep learning landscape and talks about his latest work on Multi-task Deep Neural Networks, Unified Language Modeling and vision-language pre-training. He also unpacks the science behind task-oriented dialog systems as well as social chatbots like Microsoft Xiaoice, and gives us some great book recommendations along the way! https://www.microsoft.com/research
Today's episode will be about deep learning and reasoning. There has been a lot of discussion about the effectiveness of deep learning models and their capability to generalize, not only across domains but also on data that such models have never seen. But there is a research group from the Department of Computer Science, Duke University that seems to be on something with deep learning and interpretability in computer vision. References Prediction Analysis Lab Duke University https://users.cs.duke.edu/~cynthia/lab.html This looks like that: deep learning for interpretable image recognition https://arxiv.org/abs/1806.10574
Alain Tapp is a veteran in technology, having done his masters in Cryptography, then a PhD in Quantum Computing and is now working on AI & Deep Learning. Alain details how machine learning works, and what are some of the approaches to training machines to "learn" and interpret. From machines understanding metaphors and sarcasm to passing the Turing test, there are still many unreachable areas of natural language processing by machines. Reinforcement Learning and the Deep Neural Networks could be the future of machine learning which could generally make an AI smarter over time. This is a great interview and a must listen for all AI & Machine Learning enthusiasts. Listen, subscribe, and review Future Tech Podcast. Contribute Bitcoin to fuel our interviews and keep us going!
© 2020-2026 Ivy Podcast Discovery LLC

