
Distributed data processing framework
POPULARITY
Categories

94 episodes with hadoop

17 episodes with hadoop

12 episodes with hadoop

26 episodes with hadoop

19 episodes with hadoop

8 episodes with hadoop

8 episodes with hadoop

4 episodes with hadoop

16 episodes with hadoop

4 episodes with hadoop

5 episodes with hadoop

6 episodes with hadoop

7 episodes with hadoop

9 episodes with hadoop

5 episodes with hadoop

5 episodes with hadoop

3 episodes with hadoop

3 episodes with hadoop

3 episodes with hadoop

9 episodes with hadoop

3 episodes with hadoop

3 episodes with hadoop

12 episodes with hadoop

2 episodes with hadoop

5 episodes with hadoop

2 episodes with hadoop

3 episodes with hadoop

2 episodes with hadoop

4 episodes with hadoop

2 episodes with hadoop

6 episodes with hadoop

3 episodes with hadoop

3 episodes with hadoop

2 episodes with hadoop

6 episodes with hadoop

2 episodes with hadoop

4 episodes with hadoop

4 episodes with hadoop

3 episodes with hadoop

6 episodes with hadoop

7 episodes with hadoop

4 episodes with hadoop

2 episodes with hadoop

3 episodes with hadoop

2 episodes with hadoop

5 episodes with hadoop

2 episodes with hadoop

2 episodes with hadoop

5 episodes with hadoop

35 episodes with hadoop

2 episodes with hadoop

3 episodes with hadoop

2 episodes with hadoop

4 episodes with hadoop

For a hundred episodes, the data world has been told data is the center of the universe. It isn't — and three of the most credible voices in the industry are finally saying so out loud. Malcolm Hawker sits down with Scott Taylor, Juan Sequeda, and Samir Sharma for a milestone roundtable: why AI isn't Hadoop, why CDOs keep failing for the same reasons, and what it's going to take to survive what's coming.

SaaS Scaled - Interviews about SaaS Startups, Analytics, & Operations
Today, we're joined by Harsha Chintalapani, Co-Founder and CTO of Collate, an AI-native semantic intelligence platform. We talk about:Solving complex data challenges to drive success at UberThe dream of getting LLMs to identify context for improved semanticsThe challenges in applying meaning and semantics at the metadata levelHow open source attracts talentThe value of retaining the ability to model in the new world of AI-generated code

In this talk, Slawomir Tulski, Data Leadership Consultant and former Meta Data Engineering Manager, shares his ten-year journey through the evolution of data systems—from researching glaciers in Poland to scaling the ads ranking infrastructure at one of the world's largest tech giants. We explore the shifting definition of the Data Engineer, the "Actionable Data" philosophy, and how to navigate the 2026 hiring market amidst the rise of AI.You'll learn about:- How to distinguish between Platform DE, Product DE, and Analytics Engineering.- Why most teams over-engineer their stacks and how to build "Value-First" instead of "Tool-First."- Why being "cloud-cost-conscious" is the most underrated competitive advantage in modern data teams.- How to identify "Legacy Traps" and choose a company culture that fosters growth.- Why strategic builders will thrive while "DBT Monkeys" and manual triaging roles are at risk of automation.- How to frame side projects and end-to-end "Toy Platforms" to stand out to recruiters without a Big Tech pedigree.TIMECODES:00:00 From Measuring Glaciers to London's Tech Scene06:47 Hadoop vs. AI: Lessons from the Original Big Data Hype11:54 The Data Identity Crisis: Platform vs. Product Engineering17:29 Tech-Native vs. Tech-by-Necessity Company Cultures25:33 The Competitive Advantage of Cost-Aware Engineering30:56 Avoiding Over-Engineered Platforms and Modern Data Stacks38:01 The Real-Time Myth: When to Use Kafka and Spark42:08 Breaking into Data Engineering: 2026 Market Reality51:04 AI Automation: Why Strategic Builders Outlast "DBT Monkeys"57:35 Portfolio Strategy: Framing Side Projects for Maximum Impact1:04:42 The Ultimate Portfolio Project: Building End-to-End Platforms1:07:49 Networking Advice and Local Gdansk CultureThis talk is designed for ambitious data professionals including engineers, analysts, and career-switchers who want a pragmatic, "fluff-free" roadmap for surviving and thriving in the 2026 data landscape. It is particularly valuable for hiring managers and senior leaders looking to audit their recruitment processes, as well as those in traditional corporate environments seeking to implement the agile, high-impact engineering cultures found in Big Tech giants like Meta.Connect with Slawomir:- Linkedin - https://www.linkedin.com/in/slawomir-tulski-091611116/- Form for DE role Ebook - https://docs.google.com/forms/d/e/1FAIpQLSdSCLaBdTtuRlgV_nukKckumR60VOovECtlRIRI5DMUIk36EQ/viewform?usp=dialogConnect with DataTalks.Club:- Join the community - https://datatalks.club/slack.html- Subscribe to our Google calendar to have all our events in your calendar - https://calendar.google.com/calendar/r?cid=ZjhxaWRqbnEwamhzY3A4ODA5azFlZ2hzNjBAZ3JvdXAuY2FsZW5kYXIuZ29vZ2xlLmNvbQ- Check other upcoming events - https://lu.ma/dtc-events- GitHub: https://github.com/DataTalksClub- LinkedIn - https://www.linkedin.com/company/datatalks-club/ - Twitter - https://twitter.com/DataTalksClub - Website - https://datatalks.club/

Collate is building a semantic intelligence platform that unifies fragmented metadata tooling across the modern data stack. With 12,000+ community members, 3,000+ open source deployments, and 400+ code contributors, the company has proven that open source can be a systematic GTM engine, not just a distribution tactic. In this episode of BUILDERS, I sat down with Suresh Srinivas, Co-Founder & CEO of Collate, to explore his journey from the Hadoop core team at Yahoo, through founding Hortonworks, to architecting data systems processing 4 trillion events daily at Uber—and why that experience led him to rebuild metadata infrastructure from scratch. Topics Discussed: Why platform builders at Yahoo and Hortonworks struggled to drive business value despite powerful technology The metadata fragmentation problem: how siloed tools lack unified vocabularies and end-to-end context Collate's contrarian decision to build Open Metadata from zero rather than spinning out Uber's internal tooling Engineering an open core GTM model that generates nearly 100% inbound sales from technical practitioners Scaling community contribution: moving from feedback loops to 400+ code contributors Hiring a CMO to translate technical value into business-leader messaging without losing practitioner trust The convergence thesis: structured data, knowledge graphs, and semantic layers as the foundation for reliable AI GTM Lessons For B2B Founders: Architect your open source for GTM leverage, not just distribution: Suresh built Open Metadata as a unified platform consolidating data discovery, observability, and governance—previously fragmented across multiple tools. This architectural decision created natural upgrade paths to Collate's managed offering. The lesson: open source architecture should solve a complete job-to-be-done that reveals commercial value through usage, not just demonstrate technical capability. 100+ daily practitioner conversations beats any user research: Collate maintains ongoing dialogue with their community across Snowflake, Databricks, and other integrations. Suresh called this "a product manager's dream"—immediate feedback on what breaks, what's missing, and what workflow improvements matter. For infrastructure startups, this beat rate of validated learning is nearly impossible to replicate through traditional customer development. High-velocity releases build credibility faster than pedigree: Starting from scratch without Yahoo or Uber's brand meant proving commitment through shipping cadence. Collate's strategy: demonstrate you'll be around and responsive before asking for production deployments. This matters more in open source than closed-source where sales cycles force commitment conversations earlier. Separate technical-buyer and business-buyer GTM motions explicitly: Collate's founding team spoke fluently to data engineers and architects who lived the metadata problem daily. Their CMO hire (after establishing product-market fit) brought expertise in articulating business impact—ROI on data initiatives, compliance risk reduction, AI readiness—without the founders faking business-speak. The timing matters: hire for the motion you're entering, not the one you're in. Play the long game with builder-culture companies: At Uber, internal tools were 2-3 years ahead of vendor solutions but became technical debt as teams moved to new problems. Suresh's advice: "Keep in touch with these larger companies. Your technology will improve and you will have better conversation with larger technical companies." The wedge is timing—catch them when maintenance burden outweighs building pride, typically 24-36 months post-launch. Design for all company scales from day one: Unlike Uber's internal metadata platform built for massive scale with corresponding complexity, Open Metadata works for small teams through enterprises. This wasn't just good design—it was GTM expansion strategy. Building only for scale locks you into enterprise-only sales. Building only for simplicity caps your ACV. The middle path requires architectural discipline upfront. // Sponsors: Front Lines — We help B2B tech companies launch, manage, and grow podcasts that drive demand, awareness, and thought leadership. www.FrontLines.io The Global Talent Co. — We help tech startups find, vet, hire, pay, and retain amazing marketing talent that costs 50-70% less than the US & Europe. www.GlobalTalent.co // Don't Miss: New Podcast Series — How I Hire Senior GTM leaders share the tactical hiring frameworks they use to build winning revenue teams. Hosted by Andy Mowat, who scaled 4 unicorns from $10M to $100M+ ARR and launched Whispered to help executives find their next role. Subscribe here: https://open.spotify.com/show/53yCHlPfLSMFimtv0riPyM

Enterprise AI doesn't fail because models are weak. It fails because data pipelines break, permissions drift, costs explode, and governance is treated like an annual checkbox instead of everyday operational discipline.In this episode of Intelligent Indians!, Vikram Vaidyanathan sits down with Rohit Choudhury, Founder & CEO of Acceldata, for a deep conversation on how enterprise data systems actually behave at scale and why AI makes every weak foundation visible.Rohit's founder journey mirrors the last 15 years of data infrastructure: from scaling InMobi in the pre-cloud era, to the Hadoop days at Hortonworks, to pioneering data observability, and now pushing into Agentic Data Management as enterprises move from AI pilots to production.The conversation goes deep into:1. Why AI POCs often work in one team but collapse at enterprise scale 2. The real cost of fixing data late, and why ingestion is the only place to fix it3. How AI agents change the stakes: real-time failures, hallucinations explainability and ai updates4. A practical playbook for CIOs and CDOs: SLAs, rapid experimentation, and leadership upskilling5. Why cost control is becoming existential, from reruns to cloud bills to private/hybrid AIThe “India edge” in building global enterprise companies, and what DPI × AI could unlock nextWatch the full episode to understand what it really takes to make AI work at enterprise scale.Chapters:00:00 Why AI POCs Fail at Scale in Enterprises02:30 Introducing Rohit Choudhury (Acceldata Founder)05:30 Early Days at InMobi & Rewriting the Stack 3 Times08:30 First Startup Failure & Learning Customer Obsession11:30 Birth of the Data Observability Category14:30 How Enterprise Data Pipelines Really Work (1000+ Apps)18:00 Why Enterprises Need End-to-End Data Visibility21:00 COVID Story & Missed Investment Moment24:00 Why hallucinations are dangerous for enterprises27:00 Governance in AI30:00 How Banks Should Prepare for AI at Scale (4 Steps)33:30 Why Leaders Must Learn AI Themselves (Cursor Story)36:30 From Tool Sprawl to One Agentic Platform39:30 Cost Explosion: Cloud vs Private AI42:30 Self-Healing Data & Preventing AI Hallucinations45:00 – Future of Enterprise AI & Closing ThoughtsFollow Z47Website - https://www.z47.com/Instagram - https://www.instagram.com/z47.vc/LinkedIn - https://www.linkedin.com/company/z47-vc/#podcast #podcasts #future #ai #aiindia #aicourses #aiupdates

Security, compliance, and resilience are the cornerstones of trust. In this episode, Lois Houston and Nikita Abraham continue their conversation with David Mills and Tijo Thomas, exploring how Oracle Cloud Infrastructure empowers organizations to protect data, stay compliant, and scale with confidence. Real-world examples from Zoom, KDDI, 8x8, and Uber highlight these capabilities. Cloud Business Jumpstart: https://mylearn.oracle.com/ou/course/cloud-business-jumpstart/152957 Oracle University Learning Community: https://education.oracle.com/ou-community LinkedIn: https://www.linkedin.com/showcase/oracle-university/ X: https://x.com/Oracle_Edu Special thanks to Arijit Ghosh, David Wright, Kris-Ann Nansen, Radhika Banka, and the OU Studio Team for helping us create this episode. ------------------------------------------------------------- Episode Transcript: 00:00 Welcome to the Oracle University Podcast, the first stop on your cloud journey. During this series of informative podcasts, we'll bring you foundational training on the most popular Oracle technologies. Let's get started! 00:26 Lois: Hello and welcome to the Oracle University Podcast! I'm Lois Houston, Director of Communications and Adoption with Customer Success Services, and with me is Nikita Abraham, Team Lead: Editorial Services with Oracle University. Nikita: Hi everyone! In our last episode, we started the conversation around the real business value of Oracle Cloud Infrastructure and how it helps organizations create impact at scale. Lois: Today, we're taking a closer look at what keeps the value strong — things like security, compliance, and the technology that helps businesses stay resilient. To walk us through it, we have our experts from Oracle University, David Mills, Senior Principal PaaS Instructor, and Tijo Thomas, Principal OCI Instructor. 01:12 Nikita: Hi David and Tijo! It's great to have you both here! Tijo, let's start with you. How does Oracle Cloud Infrastructure help organizations stay secure? Tijo: OCI uses a security first approach to protect customer workloads. This is done with implementing a Zero Trust Model. A Zero Trust security model use frequent user authentication and authorization to protect assets while continuously monitoring for potential breaches. This would assume that no users, no devices, no applications are universally trusted. Continuous verification is always required. Access is granted only based on the context of request, the level of trust, and the sensitivity of that asset. There are three strategic pillars that Oracle security first approach is built on. The first one is being automated. With automation, the business doesn't have to rely on any manual work to stay secure. Threat detection, patching, and compliance checks, all these happen automatically. And that reduces human errors and also saving time. Security in OCI is always turned on. Encryption is automatic. Identity checks are continuous. Security is not an afterthought in OCI. It is incorporated into every single layer. Now, while we talk about Oracle's security first approach, remember security is a shared responsibility, and what that means while Oracle handles the data center, the hardware, the infrastructure, software, consumers are responsible for securing their apps, configurations and the data. 03:06 Lois: Tijo, let's discuss this with an example. Imagine an online store called MuShop. They're a fast-growing business selling cat products. Can you walk us through how a business like this can enhance its end-to-end security and compliance with OCI? Tijo: First of all, focusing on securing web servers. These servers host the web portal where customers would browse, they log in, and place their orders. So these web servers are a prime target for attackers. To protect these entry points, MuShop deployed a service called OCI Web Application Firewall. On top of that, the MuShop business have also used OCI security list and network security groups that will control their traffic flow. As when the businesses grow, new users such as developers, operations, finance, staff would all need to be onboarded. OCI identity services is used to assign roles, for example, giving developers access to only the dev instances, and finance would access just the billing dashboards. MuShop also require MFA multi-factor authentication, and that use both password and a time-based authentication code to verify their identities. Talking about some of the critical customer data like emails, addresses, and the payment info, this data is stored in databases and storage. Using OCI Vault, the data is encrypted with customer managed keys. Oracle Data Safe is another service, and that is used to audit who has got access to sensitive tables, and also mask real customer data in non-production environments. 04:59 Nikita: Once those systems are in place, how can MuShop use OCI tools to detect and respond to threats quickly? Tijo: For that, MuShop used a service called OCI Cloud Guard. Think of it like a security operation center, and which is built right into OCI. It monitors the entire OCI environment continuously, and it can track identity activities, storage settings, network configurations and much more. If it finds something risky, like a publicly exposed object storage bucket, or maybe a user having a broad access to that environment, it raises a security finding. And better yet, it can automatically respond. So if someone creates a resource outside of their policy, OCI Cloud Guard can disable it. 05:48 Lois: And what about preventing misconfigurations? How does OCI make that easier while keeping operations secure? Tijo: OCI Security Zone is another service and that is used to enforce security postures in OCI. The goody zones help you to avoid any accidental misconfigurations. For example, in a security zone, you can choose users not to create a storage bucket that is publicly accessible. To stay ahead of vulnerabilities, MuShop runs OCI vulnerability scanning. They have scheduled to scan weekly to capture any outdated libraries or misconfigurations. OCI Security Advisor is another service that is used to flag any unused open ports and with recommending stronger access rules. MuShop needed more than just security. They also had to be compliant. OCI's compliance certifications have helped them to meet data privacy and security regulations across different regions and industries. There are additional services like OCI audit logs for traceability that help them pass internal and external audits. 07:11 Oracle University is proud to announce three brand new courses that will help your teams unlock the power of Redwood—the next generation design system. Redwood enhances the user experience, boosts efficiency, and ensures consistency across Oracle Fusion Cloud Applications. Whether you're a functional lead, configuration consultant, administrator, developer, or IT support analyst, these courses will introduce you to the Redwood philosophy and its business impact. They'll also teach you how to use Visual Builder Studio to personalize and extend your Fusion environment. Get started today by visiting mylearn.oracle.com. 07:52 Nikita: Welcome back! We know that OCI treats security as a continuous design principle: automated, always on, and built right into the platform. David, do you have a real-world example of a company that needed to scale rapidly and was able to do so successfully with OCI? David: In late 2019, Zoom averaged 10 million meeting participants a day. By April 2020, well that number surged to over 300 million as video conferencing became essential for schools, businesses, and families around the world due to the global pandemic. To meet that explosive demand, Zoom chose OCI not just for performance, but for the ability to scale fast. In just nine hours, OCI engineers helped Zoom move from deployment to live production, handling hundreds of thousands of concurrent meetings immediately. Within weeks, they were supporting millions. And Zoom didn't just scale, they sustained it. With OCI's next-gen architecture, Zoom avoided the performance bottlenecks common in legacy clouds. They used OCI functions and cloud native services to scale workloads flexibly and securely. Today, Zoom transfers more than seven petabytes of data per day through Oracle Cloud. That's enough bandwidth to stream HD video continuously for 93 years. And they do it while maintaining high availability, low latency, and enterprise grade security. As articulated by their CEO Erik Yuan, Zoom didn't just meet the moment, they redefined it with OCI behind the scenes. 09:45 Nikita: That's an incredible story about scale and agility. Do you have more examples of companies that turned to OCI to solve complex data or integration challenges? David: Telecom giant KDDI with over 64 million subscribers, faced a growing data dilemma. Data was everywhere. Survey results, system logs, behavioral analytics, but it was scattered across thousands of sources. Different tools for different tasks created silos, delays, and rising costs. KDDI needed a single platform to connect it all, and they chose Oracle. They replaced their legacy data systems with a modern data platform built on OCI and Autonomous Database. Now they can analyze behavior, improve service planning, and make faster, smarter decisions without the data chaos. But KDDI didn't stop there. They built a 300 terabyte data lake and connected all their systems-- custom on-prem apps, SaaS providers like Salesforce, and even multi-cloud infrastructure. Thanks to Oracle Integration and pre-built adapters, everything works together in real-time, even across clouds. AWS, Azure, and OCI now operate in harmony. The results? Reduced operational costs, faster development cycles, governance and API access improved across the board. KDDI can now analyze customer behavior to improve services like where to expand their 5G network. Next up, 8 by 8 powers communication for over 55,000 companies and 160 countries with more than 3 million users, depending on its voice, video, and messaging tools every day. To maintain that scale, they needed a cloud that could deliver low latency global availability and high performance without blowing up costs. Well, they moved their video meeting services from Amazon to OCI and went live in just four days. The results? 25% increase in performance per node, 80% reduction in network egress costs, and a significantly lower overall infrastructure spend. But this wasn't just a lift and shift. 8 by 8 also replaced legacy tools with Oracle Logging Analytics, giving their teams a single view across apps, infrastructure, and regions. 8 by 8 scaled up fast. They migrated core voice services, deployed over 300 microservices using OCI Kubernetes, and now run over 1,700 nodes across 26 global OCI regions. In addition, OCI's Ampere-based virtual machines gave them a major boost, sustaining 80% CPU utilization and more than 30% increased performance per core and with no degradation. And with OCI's Observability and Management platform, they gained real-time visibility into application health across both on-prem and cloud. Bottom line, 8x8 represents yet another excellent example of a company leveraging OCI for maximum business results. 13:24 Lois: Uber handles more than a million trips per hour, and Oracle Cloud Infrastructure is an integral part of making that possible. Can you walk us through how OCI supports Uber's needs? David: Uber, the world's largest on-demand mobility platform, handles over 1 million trips every hour. And behind the scenes, OCI is helping to make that possible. In 2023, Uber began migrating thousands of microservices, data platforms, and AI models to OCI. Why? Because OCI provides the automation, flexibility, and infrastructure scale needed to support Uber's explosive growth. Today, Uber uses OCI Compute to handle massive trips serving traffic and OCI Object Storage to replace one of the largest Hadoop-based data environments in the industry. They needed global reach and multi-cloud compatibility, and OCI delivered. But it's not just scale, it's intelligence. Uber runs dozens of AI models on OCI to support real-time predictions up 14 million per second. From ride pricing to traffic patterns, this AI layer powers every trip behind the scenes. And by shifting stateless workloads to OCI Ampere ARM Compute servers, Uber reduced cost while increasing CPU efficiency. For AI inferencing, Uber uses OCI's AI infrastructure to strike the perfect balance between speed, throughput, and cost. So the next time you use your Uber app to schedule a ride, consider what happens behind the scenes with OCI. 15:18 Lois: That's so impressive! Thank you, David, for those wonderful stories, and Tijo for all of your insights. Whether you're in strategy, finance, or transformation, we hope you're walking away with a clearer view of the business value OCI can bring. Nikita: Yeah, and if you want to learn more about the topics we discussed today, visit mylearn.oracle.com and search for the Cloud Business Jumpstart course. Until next time, this is Nikita Abraham… Lois: And Lois Houston signing off! 15:48 That's all for this episode of the Oracle University Podcast. If you enjoyed listening, please click Subscribe to get all the latest episodes. We'd also love it if you would take a moment to rate and review us on your podcast app. See you again on the next episode of the Oracle University Podcast.

It's all about Data Pipelines. Join Pure Storage Field Solution Architect Chad Hendron and Solutions Director Andrew Silifant for a deep dive into the evolution of data management, focusing on the Data Lakehouse architecture and its role in the age of AI and ML. Our discussion looks at the Data Lakehouse as a powerful combination of a data lake and a data warehouse, solving problems like "data swamps” and proprietary formats of older systems. Viewers will learn about technological advancements, such as object storage and open table formats, that have made this new architecture possible, allowing for greater standardization and multiple tooling functions to access the same data. Our guests also explore current industry trends, including a look at Dremio's 2025 report showing the rapid adoption of Data Lakehouses, particularly as a replacement for older, inefficient systems like cloud data warehouses and traditional data lakes. Gain insight into the drivers behind this migration, including the exponential growth of unstructured data and the need to control cloud expenditure by being more prescriptive about what data is stored in the cloud versus on-premises. Andrew provides a detailed breakdown of processing architectures and the critical importance of meeting SLAs to avoid costly and frustrating pipeline breaks in regulated industries like banking. Finally, we provide practical takeaways and a real-world case study. Chad shares a customer success story about replacing a large, complex Hadoop cluster with a streamlined Dremio and Pure Storage solution, highlighting the massive reduction in physical space, power consumption, and management complexity. Both guests emphasize the need for better governance practices to manage cloud spend and risk. Andrew underscores the essential, full-circle role of databases—from the "alpha" of data creation to the "omega" of feature stores and vector databases for modern AI use cases like Retrieval-Augmented Generation (RAG). Tune in to understand how a holistic data strategy, including Pure's Enterprise Data Cloud, can simplify infrastructure and future-proof your organization for the next wave of data-intensive workloads. To learn more, visit https://www.purestorage.com/solutions/ai/data-warehouse-streaming-analytics.html Check out the new Pure Storage digital customer community to join the conversation with peers and Pure experts: https://purecommunity.purestorage.com/ 00:00 Intro and Welcome 03:15 Data Lakehouse Primer 08:31 Stat of the Episode on Lakehouse Usage 10:50 Challenges with Data Pipeline access 13:58 Assessing Organization Success with Data Cleaning 16:07 Use Cases for the Data Lakehouse 20:41 Case Study on Data Lakehouse Use Case 24:11 Hot Takes Segment

Discover how Anton, one of the most experienced AI and machine learning experts in the industry, discusses his evolution from building matching algorithms at Bright.com to navigating today's AI landscape. With over a decade of experience in large-scale recommendation systems and data processing, Anton reveals how the fundamentals of big data and embarrassingly parallel computing shaped modern AI applications, and why human-centered design is now more critical than ever in building AI-powered products.Episode Timestamps:- 00:00 - Introduction and welcome- 00:47 - Anton's experience at Bright.com and the recruitment matching problem- 03:23 - The big data era, Hadoop, and Spark in the web 2.0 world- 05:00 - Embarrassingly parallel computing and large-scale data processing- 10:00 - How recommendation algorithms work at scale in recruitment- 20:00 - Evolution of the data scientist role over time- 30:00 - Building intelligent matching systems- 40:00 - Understanding user needs and organizational workflows- 50:00 - The shift toward human-centered AI design- 57:30 - Providing pre-filled content and personalization- 58:02 - Anton's vision for the future and human values- 01:01:46 - Closing thoughts on humanity and technologyAbout Anton:Anton is a veteran machine learning and AI engineer with over a decade of experience building large-scale recommendation and matching systems. He played a key role at Bright.com, a two-sided recruitment platform that pioneered transparent scoring algorithms for candidate-job matching. His expertise spans big data infrastructure, recommendation systems, user experience optimization, and the human-centered approach to AI product development.Resources Mentioned:- Hadoop and Spark (big data processing frameworks)- Big data infrastructure and cloud computing platforms- Two-sided marketplace architectures- Recommendation algorithms and matching systems- User workflow analysis toolsPartner Links:- Book Enterprise Training — https://www.upscaile.com/- Subscribe to our free newsletter — https://www.theaireport.ai/subscribe-theaireport-youtubeHashtags:#AIAgents #MachineLearningSystems #RecruitmentTechnology #BigData #DataScience #RecommendationAlgorithms #HadoopSpark #AIProductDesign #HumanCenteredAI #LargeScaleML #CloudComputing #AIStrategy #FutureOfWork #TechLeadership #CareerDevelopment
The Confluent Developer Podcast is here! For this first episode, Tim Berglund talks to his co-host, Adi Polak (Confluent), about her career in distributed data systems. Her first job: neighborhood dogwalker. Her challenge/theme: early Hadoop, working at Akamai on data optimization and real-time threat detection for huge global customers like Apple, Nike, Facebook and others, and the power of collaboration. SEASON 2 Hosted by Tim Berglund, Adi Polak and Viktor Gamov Produced and Edited by Noelle Gallagher, Peter Furia and Nurie Mohamed Music by Coastal Kites Artwork by Phil Vo
An airhacks.fm conversation with Adam Dudczak (@maneo) about: early programming experiences with Commodore 64 and Pascal, demo scene participation through postal mail swapping of floppy disks, writing assembly code for 64K intros with music and graphics, developing digital library systems using Java Servlets and Hibernate, involvement in reactivating Poznan Java User Group in 2007, NetBeans Dream Team and NetBeans World Tour, appearing on Polish breakfast TV to discuss Java programming, working at Supercomputing Center on cultural heritage digitization projects, transitioning to EJB 3.0 and Glassfish based on conference inspirations, joining allegro in 2014 to rewrite search functionality from PHP to Java microservices, handling 14K requests per second with Solr-based search infrastructure, migrating big data stack from on-premise Hadoop to Google Cloud Platform, developing private banking application for children using Spring and Hibernate then migrating to Google Sheets with 70 lines of JavaScript, discussing public cloud cost optimization strategies, comparing AWS Lambda versus EC2 versus container services based on traffic patterns, emphasizing removal of code when moving to public cloud to leverage managed services, standardization benefits of Java EE for long-term maintenance and migration, quarkus as modern framework supporting old Jakarta EE code with fast startup times, importance of choosing appropriate persistence layer (S3 vs relational databases) based on cloud costs, serverless architectures for enterprise applications with predictable low traffic, differences between AWS Azure and GCP service offerings and pricing models, Turbo assembler project klatwa Adam Dudczak on twitter: @maneo

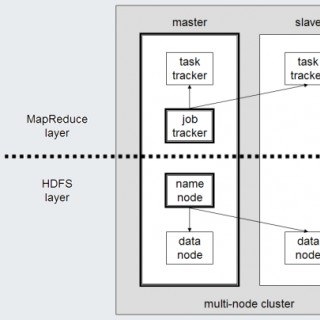
MapReduce: Ein Deep DiveIm Jahr 2004 war die Verarbeitung von großen Datenmengen eine richtige Herausforderung. Einige Firmen hatten dafür sogenannte Supercomputer. Andere haben nur mit der Schulter gezuckt und auf das Ende ihrer Berechnung gewartet. Google war einer der Player, der zwar große Datenmengen hatte und diese auch verarbeiten wollte, jedoch keine Supercomputer zur Verfügung hatte. Oder besser gesagt: Nicht das Geld in die Hand nehmen wollte.Was macht man also, wenn man ein Problem hat? Eine Lösung suchen. Das hat Jeffrey Dean und sein Team getan. Das Ergebnis? Ein revolutionäres Paper, wie man mittels MapReduce große Datenmengen verteilt auf einfacher Commodity-Hardware verarbeiten kann.In dieser Podcast-Episode schauen wir uns das mal genauer an. Wir klären, was MapReduce ist, wie es funktioniert, warum MapReduce so revolutionär war, wie es mit Hardware-Ausfällen umgegangen ist, welche Herausforderungen in der Praxis hatte bzw. immer noch hat, was das Google File System, Hadoop und HDFS damit zu tun haben und ordnen MapReduce im Kontext der heutigen Technologien mit Cloud und Co ein.Eine weitere Episode “Papers We Love”.Bonus: Hadoop ist wohl der Elefant im Raum.Unsere aktuellen Werbepartner findest du auf https://engineeringkiosk.dev/partnersDas schnelle Feedback zur Episode:

Today's guest is Shayde Christian, Chief Data & Analytics Officer at Cloudera. Founded in 2008, Cloudera believes that data can make what is impossible today, possible tomorrow. They empower people to transform complex data into clear and actionable insights. Cloudera delivers an enterprise data cloud for any data, anywhere, from the Edge to AI. Powered by the relentless innovation of the open source community, Cloudera advances digital transformation for the world's largest enterprises.Shayde leads all data and analytics functions at Cloudera, overseeing data science, machine learning, business intelligence, data architecture, data engineering, platform engineering and DevOps. He helps customers navigate their hybrid cloud migration and optimization journeys. Shayde has built or revitalized six enterprise data analytics organizations for Fortune 500 companies, global tech firms and startups.In this episode, Shayde talks about:His unique career journey, following passions and pursuing a true calling,How Cloudera evolved beyond Hadoop, pioneering AI-driven data solutions,Driving success through secure AI, data quality and feedback,Scalability, ROI, killer apps and AI-driven automation,Why attracting AI talent is hard; teams bootstrap skills internally,Why Cloudera is a great place to work with a focus on innovation and purpose,How his team aims to bridge the tech-business gap using AI,Leading the software evolution, investing in generative AI for success
Le BigDataHebdo reçoit Florian Caringi, responsable des plateformes Data & IA au sein du groupe BPCE. On discute de l'évolution des architectures Big Data, de Hadoop aux environnements hybrides et cloud, avec une adoption massive de Google Cloud (BigQuery, Vertex AI) pour des usages analytiques et data science.Florian partage son expérience sur les défis de migration, de FinOps, et l'intégration des IA génératives. Une discussion passionnante sur la modernisation des infrastructures et l'impact des nouvelles technologies dans les grandes organisations.Show notes et chapitres sur http://bigdatahebdo.com/podcast/episode-212-cloud-hybride-bpce/

This morning, a great article came across my feed that gave me PTSD, asking if Iceberg is the Hadoop of the Modern Data Stack? In this rant, I bring the discussion back to a central question you should ask with any hot technology - do you need it at all? Do you need a tool built for the top 1% of companies at a sufficient data scale? Or is a spreadsheet good enough? Link: https://blog.det.life/apache-iceberg-the-hadoop-of-the-modern-data-stack-c83f63a4ebb9
Corey Quinn chats with Miles Ward, CTO of SADA, about SADA's recent acquisition by Insight and its impact on scaling the company's cloud services. Ward explains how Insight's backing allows SADA to take on more complex projects, such as multi-cloud migrations and data center transitions. They also discuss AI's growing role in business, the challenges of optimizing cloud AI costs, and the differences between cloud-to-cloud and data center migrations. Corey and Miles also share their takes on domain registrars and Corey gives a glimpse into his Raspberry Pi Kubernetes setup.Show Highlights(00:00) Intro(00:48) Backblaze sponsor read(2:04) Google's support of SADA being acquired by Insight(2:44) How the skills SADA invested in affects the cases they accept (5:14) Why it's easier to migrate from one cloud to another than from data center to cloud(7:06) Customer impact from the Broadcom pricing changes(10:40) The current cost of AI(13:55) Why the scale of AI makes it difficult to understand its current business impact(15:43) The challenges of monetizing AI(17:31) Micro and macro scale perspectives of AI(21:16) Amazon's new habit of slowly killing of services(26:55) Corey's policy to never use a domain registrar with the word “daddy” in their name(32:46) Where to find more from Miles and SADAAbout Miles WardAs Chief Technology Officer at SADA, Miles Ward leads SADA's cloud strategy and solutions capabilities. His remit includes delivering next-generation solutions to challenges in big data and analytics, application migration, infrastructure automation, and cost optimization; reinforcing our engineering culture; and engaging with customers on their most complex and ambitious plans around Google Cloud.Previously, Miles served as Director and Global Lead for Solutions at Google Cloud. He founded the Google Cloud's Solutions Architecture practice, launched hundreds of solutions, built Style-Detection and Hummus AI APIs, built CloudHero, designed the pricing and TCO calculators, and helped thousands of customers like Twitter who migrated the world's largest Hadoop cluster to public cloud and Audi USA who re-platformed to k8s before it was out of alpha, and helped Banco Itau design the intercloud architecture for the bank of the future.Before Google, Miles helped build the AWS Solutions Architecture team. He wrote the first AWS Well-Architected framework, proposed Trusted Advisor and the Snowmobile, invented GameDay, worked as a core part of the Obama for America 2012 “tech” team, helped NASA stream the Curiosity Mars Rover landing, and rebooted Skype in a pinch.Earning his Bachelor of Science in Rhetoric and Media Studies from Willamette University, Miles is a three-time technology startup entrepreneur who also plays a mean electric sousaphone.LinksProfessional site: https://sada.com/ LinkedIn: https://www.linkedin.com/in/milesward/ Twitter: https://twitter.com/mileswardSponsorBackblaze: https://www.backblaze.com/
In this Screaming in the Cloud Replay, we're revisiting our conversation with Miles War — perhaps the closest thing Google Cloud has to Corey Quinn. With a wit and sharpness at hand, and an entire backup retinue of trumpets, trombones, and various brass horns, Miles is here to join the conversation about what all is going on at Google Cloud. Miles breaks down SADA and their partnership with Google Cloud. He goes into some details on what GCP has been up to, and talks about the various areas they are capitulating forward. Miles talks about working with Thomas Kurian, who is the only who counts since he follows Corey on Twitter, and the various profundities that GCP has at hand.Show Highlights:(0:00) Intro(1:38) Sonrai Security sponsor read(2:40) Reliving Google Cloud Next 2021(7:24) Unlikable, yet necessary change at Google(11:41) Lack of Focus in the Cloud(18:03) Google releases benefitting developers(20:57) The rise of distributed databases(24:12) Backblaze sponsor read(24:41) Arguments for (and against) going multi-cloud(26:49) The problem with Google Cloud outages(33:01) Data transfer fees(37:49) Where you can find more from MilesAbout Miles WardAs Chief Technology Officer at SADA, Miles Ward leads SADA's cloud strategy and solutions capabilities. His remit includes delivering next-generation solutions to challenges in big data and analytics, application migration, infrastructure automation, and cost optimization; reinforcing our engineering culture; and engaging with customers on their most complex and ambitious plans around Google Cloud.Previously, Miles served as Director and Global Lead for Solutions at Google Cloud. He founded the Google Cloud's Solutions Architecture practice, launched hundreds of solutions, built Style-Detection and Hummus AI APIs, built CloudHero, designed the pricing and TCO calculators, and helped thousands of customers like Twitter who migrated the world's largest Hadoop cluster to public cloud and Audi USA who re-platformed to k8s before it was out of alpha, and helped Banco Itau design the intercloud architecture for the bank of the future.Before Google, Miles helped build the AWS Solutions Architecture team. He wrote the first AWS Well-Architected framework, proposed Trusted Advisor and the Snowmobile, invented GameDay, worked as a core part of the Obama for America 2012 “tech” team, helped NASA stream the Curiosity Mars Rover landing, and rebooted Skype in a pinch.Earning his Bachelor of Science in Rhetoric and Media Studies from Willamette University, Miles is a three-time technology startup entrepreneur who also plays a mean electric sousaphone.Links:SADA.com: https://sada.comTwitter: https://twitter.com/mileswardEmail: miles@sada.comOriginal episode:https://www.lastweekinaws.com/podcast/screaming-in-the-cloud/gcp-s-many-profundities-with-miles-ward/SponsorsSonrai Security: sonrai.co/access24Backblaze: backblaze.com
0:00 hi everyone Welcome to our event this event is brought to you by data dos club which is a community of people who love 0:06 data and we have weekly events and today one is one of such events and I guess we 0:12 are also a community of people who like to wake up early if you're from the states right Christopher or maybe not so 0:19 much because this is the time we usually have uh uh our events uh for our guests 0:27 and presenters from the states we usually do it in the evening of Berlin time but yes unfortunately it kind of 0:34 slipped my mind but anyways we have a lot of events you can check them in the 0:41 description like there's a link um I don't think there are a lot of them right now on that link but we will be 0:48 adding more and more I think we have like five or six uh interviews scheduled so um keep an eye on that do not forget 0:56 to subscribe to our YouTube channel this way you will get notified about all our future streams that will be as awesome 1:02 as the one today and of course very important do not forget to join our community where you can hang out with 1:09 other data enthusiasts during today's interview you can ask any question there's a pin Link in live chat so click 1:18 on that link ask your question and we will be covering these questions during the interview now I will stop sharing my 1:27 screen and uh there is there's a a message in uh and Christopher is from 1:34 you so we actually have this on YouTube but so they have not seen what you wrote 1:39 but there is a message from to anyone who's watching this right now from Christopher saying hello everyone can I 1:46 call you Chris or you okay I should go I should uh I should look on YouTube then okay yeah but anyways I'll you don't 1:53 need like you we'll need to focus on answering questions and I'll keep an eye 1:58 I'll be keeping an eye on all the question questions so um 2:04 yeah if you're ready we can start I'm ready yeah and you prefer Christopher 2:10 not Chris right Chris is fine Chris is fine it's a bit shorter um 2:18 okay so this week we'll talk about data Ops again maybe it's a tradition that we talk about data Ops every like once per 2:25 year but we actually skipped one year so because we did not have we haven't had 2:31 Chris for some time so today we have a very special guest Christopher Christopher is the co-founder CEO and 2:37 head chef or hat cook at data kitchen with 25 years of experience maybe this 2:43 is outdated uh cuz probably now you have more and maybe you stopped counting I 2:48 don't know but like with tons of years of experience in analytics and software engineering Christopher is known as the 2:55 co-author of the data Ops cookbook and data Ops Manifesto and it's not the 3:00 first time we have Christopher here on the podcast we interviewed him two years ago also about data Ops and this one 3:07 will be about data hops so we'll catch up and see what actually changed in in 3:13 these two years and yeah so welcome to the interview well thank you for having 3:19 me I'm I'm happy to be here and talking all things related to data Ops and why 3:24 why why bother with data Ops and happy to talk about the company or or what's changed 3:30 excited yeah so let's dive in so the questions for today's interview are prepared by Johanna berer as always 3:37 thanks Johanna for your help so before we start with our main topic for today 3:42 data Ops uh let's start with your ground can you tell us about your career Journey so far and also for those who 3:50 have not heard have not listened to the previous podcast maybe you can um talk 3:55 about yourself and also for those who did listen to the previous you can also maybe give a summary of what has changed 4:03 in the last two years so we'll do yeah so um my name is Chris so I guess I'm 4:09 a sort of an engineer so I spent about the first 15 years of my career in 4:15 software sort of working and building some AI systems some non- AI systems uh 4:21 at uh Us's NASA and MIT linol lab and then some startups and then um 4:30 Microsoft and then about 2005 I got I got the data bug uh I think you know my 4:35 kids were small and I thought oh this data thing was easy and I'd be able to go home uh for dinner at 5 and life 4:41 would be fine um because I was a big you started your own company right and uh it didn't work out that way 4:50 and um and what was interesting is is for me it the problem wasn't doing the 4:57 data like I we had smart people who did data science and data engineering the act of creating things it was like the 5:04 systems around the data that were hard um things it was really hard to not have 5:11 errors in production and I would sort of driving to work and I had a Blackberry at the time and I would not look at my 5:18 Blackberry all all morning I had this long drive to work and I'd sit in the parking lot and take a deep breath and 5:24 look at my Blackberry and go uh oh is there going to be any problems today and I'd be and if there wasn't I'd walk and 5:30 very happy um and if there was I'd have to like rce myself um and you know and 5:36 then the second problem is the team I worked for we just couldn't go fast enough the customers were super 5:42 demanding they didn't care they all they always thought things should be faster and we are always behind and so um how 5:50 do you you know how do you live in that world where things are breaking left and right you're terrified of making errors 5:57 um and then second you just can't go fast enough um and it's preh Hadoop era 6:02 right it's like before all this big data Tech yeah before this was we were using 6:08 uh SQL Server um and we actually you know we had smart people so we we we 6:14 built an engine in SQL Server that made SQL Server a column or 6:20 database so we built a column or database inside of SQL Server um so uh 6:26 in order to make certain things fast and and uh yeah it was it was really uh it's not 6:33 bad I mean the principles are the same right before Hadoop it's it's still a database there's still indexes there's 6:38 still queries um things like that we we uh at the time uh you would use olap 6:43 engines we didn't use those but you those reports you know are for models it's it's not that different um you know 6:50 we had a rack of servers instead of the cloud um so yeah and I think so what what I 6:57 took from that was uh it's just hard to run a team of people to do do data and analytics and it's not 7:05 really I I took it from a manager perspective I started to read Deming and 7:11 think about the work that we do as a factory you know and in a factory that produces insight and not automobiles um 7:18 and so how do you run that factory so it produces things that are good of good 7:24 quality and then second since I had come from software I've been very influenced 7:29 by by the devops movement how you automate deployment how you run in an agile way how you 7:35 produce um how you how you change things quickly and how you innovate and so 7:41 those two things of like running you know running a really good solid production line that has very low errors 7:47 um and then second changing that production line at at very very often they're kind of opposite right um and so 7:55 how do you how do you as a manager how do you technically approach that and 8:00 then um 10 years ago when we started data kitchen um we've always been a profitable company and so we started off 8:07 uh with some customers we started building some software and realized that we couldn't work any other way and that 8:13 the way we work wasn't understood by a lot of people so we had to write a book and a Manifesto to kind of share our our 8:21 methods and then so yeah we've been in so we've been in business now about a little over 10 8:28 years oh that's cool and uh like what 8:33 uh so let's talk about dat offs and you mentioned devops and how you were inspired by that and by the way like do 8:41 you remember roughly when devops as I think started to appear like when did people start calling these principles 8:49 and like tools around them as de yeah so agile Manifesto well first of all the I 8:57 mean I had a boss in 1990 at Nasa who had this idea build a 9:03 little test a little learn a lot right that was his Mantra and then which made 9:09 made a lot of sense um and so and then the sort of agile software Manifesto 9:14 came out which is very similar in 2001 and then um the sort of first real 9:22 devops was a guy at Twitter started to do automat automated deployment you know 9:27 push a button and that was like 200 Nish and so the first I think devops 9:33 Meetup was around then so it's it's it's been 15 years I guess 6 like I was 9:39 trying to so I started my career in 2010 so I my first job was a Java 9:44 developer and like I remember for some things like we would just uh SFTP to the 9:52 machine and then put the jar archive there and then like keep our fingers crossed that it doesn't break uh uh like 10:00 it was not really the I wouldn't call it this way right you were deploying you 10:06 had a Dey process I put it yeah 10:11 right was that so that was documented too it was like put the jar on production cross your 10:17 fingers I think there was uh like a page on uh some internal Viki uh yeah that 10:25 describes like with passwords and don't like what you should do yeah that was and and I think what's interesting is 10:33 why that changed right and and we laugh at it now but that was why didn't you 10:38 invest in automating deployment or a whole bunch of automated regression 10:44 tests right that would run because I think in software now that would be rare 10:49 that people wouldn't use C CD they wouldn't have some automated tests you know functional 10:56 regression tests that would be the exception whereas that the norm at the beginning of your career and so that's 11:03 what's interesting and I think you know if we if we talk about what's changed in the last two three years I I think it is 11:10 getting more standard there are um there's a lot more companies who are 11:15 talking data Ops or data observability um there's a lot more tools that are a lot more people are 11:22 using get in data and analytics than ever before I think thanks to DBT um and 11:29 there's a lot of tools that are I think getting more code Centric right that 11:35 they're not treating their configuration like a black box there there's several 11:41 bi tools that tout the fact that they that they're uh you know they're they're git Centric you know and and so and that 11:49 they're testable and that they have apis so things like that I think people maybe let's take a step back and just do a 11:57 quick summary of what data Ops data Ops is and then we can talk about like what changed in the last two years sure so I 12:06 guess it starts with a problem and that it's it sort of 12:11 admits some dark things about data and analytics and that we're not really successful and we're not really happy um 12:19 and if you look at the statistics on sort of projects and problems and even 12:25 the psychology like I think about a year or two we did a survey of 12:31 data Engineers 700 data engineers and 78% of them wanted their job to come with a therapist and 50% were thinking 12:38 of leaving the career altogether and so why why is everyone sort of unhappy well I I I think what happens is 12:46 teams either fall into two buckets they're sort of heroic teams who 12:52 are doing their they're working night and day they're trying really hard for their customer um and then they get 13:01 burnt out and then they quit honestly and then the second team have wrapped 13:06 their projects up in so much process and proceduralism and steps that doing 13:12 anything is sort of so slow and boring that they again leave in frustration um 13:18 or or live in cynicism and and that like the only outcome is quit and 13:24 start uh woodworking yeah the only outcome really is quit and start working 13:29 and um as a as a manager I always hated that right because when when your team 13:35 is either full of heroes or proceduralism you always have people who have the whole system in their head 13:42 they're certainly key people and then when they leave they take all that knowledge with them and then that 13:48 creates a bottleneck and so both of which are aren aren't and I think the 13:53 main idea of data Ops is there's a balance between fear and herois 14:00 that you can live you don't you know you don't have to be fearful 95% of the time maybe one or two% it's good to be 14:06 fearful and you don't have to be a hero again maybe one or two per it's good to be a hero but there's a balance um and 14:13 and in that balance you actually are much more prod

A veteran of early Twitter's fail whale wars, Dmitriy joins the show to chat about the time when 70% of the Hadoop cluster got accidentally deleted, the financial reality of writing a book, and how to navigate acquisitions. Segments: (00:00:00) The Infamous Hadoop Outage (00:02:36) War Stories from Twitter's Early Days (00:04:47) The Fail Whale Era (00:06:48) The Hadoop Cluster Shutdown (00:12:20) “First Restore the Service Then Fix the Problem. Not the Other Way Around.” (00:14:10) War Rooms and Organic Decision-Making (00:16:16) The Importance of Communication in Incident Management (00:19:07) That Time When the Data Center Caught Fire (00:21:45) The "Best Email Ever" at Twitter (00:25:34) The Importance of Failing (00:27:17) Distributed Systems and Error Handling (00:29:49) The Missing README (00:33:13) Agile and Scrum (00:38:44) The Financial Reality of Writing a Book (00:43:23) Collaborative Writing Is Like Open-Source Coding (00:44:41) Finding a Publisher and the Role of Editors (00:50:33) Defining the Tone and Voice of the Book (00:54:23) Acquisitions from an Engineer's Perspective (00:56:00) Integrating Acquired Teams (01:02:47) Technical Due Diligence (01:04:31) The Reality of System Implementation (01:06:11) Integration Challenges and Gotchas Show Notes: - Dmitriy Ryaboy on Twitter: https://x.com/squarecog - The Missing README: https://www.amazon.com/Missing-README-Guide-Software-Engineer/dp/1718501838 - Chris Riccomini on how to write a technical book: https://cnr.sh/essays/how-to-write-a-technical-book Stay in touch: - Make Ronak's day by signing up for our newsletter to get our favorites parts of the convo straight to your inbox every week :D https://softwaremisadventures.com/ Music: Vlad Gluschenko — Forest License: Creative Commons Attribution 3.0 Unported: https://creativecommons.org/licenses/by/3.0/deed.en

Aravind was a Staff Software Engineer at Uber, and currently works at OpenAI.Apple Podcasts | Spotify | Google PodcastsEdited TranscriptCan you tell us about the scale of data Uber was dealing with when you joined in 2018, and how it evolved?When I joined Uber in mid-2018, we were handling a few petabytes of data. The company was going through a significant scaling journey, both in terms of launching in new cities and the corresponding increase in data volume. By the time I left, our data had grown to over an exabyte. To put it in perspective, the amount of data grew by a factor of about 20 in just a three to four-year period.Currently, Uber ingests roughly a petabyte of data daily. This includes some replication, but it's still an enormous amount. About 60-70% of this is raw data, coming directly from online systems or message buses. The rest is derived data sets and model data sets built on top of the raw data.That's an incredible amount of data. What kinds of insights and decisions does this enable for Uber?This scale of data enables a wide range of complex analytics and data-driven decisions. For instance, we can analyze how many concurrent trips we're handling throughout the year globally. This is crucial for determining how many workers and CPUs we need running at any given time to serve trips worldwide.We can also identify trends like the fastest growing cities or seasonal patterns in traffic. The vast amount of historical data allows us to make more accurate predictions and spot long-term trends that might not be visible in shorter time frames.Another key use is identifying anomalous user patterns. For example, we can detect potentially fraudulent activities like a single user account logging in from multiple locations across the globe. We can also analyze user behavior patterns, such as which cities have higher rates of trip cancellations compared to completed trips.These insights don't just inform day-to-day operations; they can lead to key product decisions. For instance, by plotting heat maps of trip coordinates over a year, we could see overlapping patterns that eventually led to the concept of Uber Pool.How does Uber manage real-time versus batch data processing, and what are the trade-offs?We use both offline (batch) and online (real-time) data processing systems, each optimized for different use cases. For real-time analytics, we use tools like Apache Pinot. These systems are optimized for low latency and quick response times, which is crucial for certain applications.For example, our restaurant manager system uses Pinot to provide near-real-time insights. Data flows from the serving stack to Kafka, then to Pinot, where it can be queried quickly. This allows for rapid decision-making based on very recent data.On the other hand, our offline flow uses the Hadoop stack for batch processing. This is where we store and process the bulk of our historical data. It's optimized for throughput – processing large amounts of data over time.The trade-off is that real-time systems are generally 10 to 100 times more expensive than batch systems. They require careful tuning of indexes and partitioning to work efficiently. However, they enable us to answer queries in milliseconds or seconds, whereas batch jobs might take minutes or hours.The choice between batch and real-time depends on the specific use case. We always ask ourselves: Does this really need to be real-time, or can it be done in batch? The answer to this question goes a long way in deciding which approach to use and in building maintainable systems.What challenges come with maintaining such large-scale data systems, especially as they mature?As data systems mature, we face a range of challenges beyond just handling the growing volume of data. One major challenge is the need for additional tools and systems to manage the complexity.For instance, we needed to build tools for data discovery. When you have thousands of tables and hundreds of users, you need a way for people to find the right data for their needs. We built a tool called Data Book at Uber to solve this problem.Governance and compliance are also huge challenges. When you're dealing with sensitive customer data, you need robust systems to enforce data retention policies and handle data deletion requests. This is particularly challenging in a distributed system where data might be replicated across multiple tables and derived data sets.We built an in-house lineage system to track which workloads derive from what data. This is crucial for tasks like deleting specific data across the entire system. It's not just about deleting from one table – you need to track down and update all derived data sets as well.Data deletion itself is a complex process. Because most files in the batch world are kept immutable for efficiency, deleting data often means rewriting entire files. We have to batch these operations and perform them carefully to maintain system performance.Cost optimization is an ongoing challenge. We're constantly looking for ways to make our systems more efficient, whether that's by optimizing our storage formats, improving our query performance, or finding better ways to manage our compute resources.How do you see the future of data infrastructure evolving, especially with recent AI advancements?The rise of AI and particularly generative AI is opening up new dimensions in data infrastructure. One area we're seeing a lot of activity in is vector databases and semantic search capabilities. Traditional keyword-based search is being supplemented or replaced by embedding-based semantic search, which requires new types of databases and indexing strategies.We're also seeing increased demand for real-time processing. As AI models become more integrated into production systems, there's a need to handle more GPUs in the serving flow, which presents its own set of challenges.Another interesting trend is the convergence of traditional data analytics with AI workloads. We're starting to see use cases where people want to perform complex queries that involve both structured data analytics and AI model inference.Overall, I think we're moving towards more integrated, real-time, and AI-aware data infrastructure. The challenge will be balancing the need for advanced capabilities with concerns around cost, efficiency, and maintainability. This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.softwareatscale.dev
Justin Borgman, Co-Founder and CEO of Starburst, explores the cutting-edge world of data management and analytics. Justin shares insights into Starburst's innovative use of Trino and Apache Iceberg, revolutionizing data warehousing and analytics. Learn about the company's journey, the evolution of data lakes, and the role of data science in modern enterprises. Episode Overview: In Episode 86 of Great Things with Great Tech, Anthony Spiteri chats with Justin Borgman, Co-Founder and CEO of Starburst. This episode dives into the transformative world of data management and analytics, exploring how Starburst leverages cutting-edge technologies like Trino and Apache Iceberg to revolutionize data warehousing. Justin shares his journey from founding Hadapt to leading Starburst, the evolution of data lakes, and the critical role of data science in today's tech landscape. Key Topics Discussed: Starburst's Origins and Vision: Justin discusses the founding of Starburst and the vision to democratize data access and eliminate data silos. Trino and Iceberg: The importance of Trino as a SQL query engine and Iceberg as an open table format in modern data management. Data Democratization: How Starburst enables organizations to perform high-performance analytics on data stored anywhere, avoiding vendor lock-in. Data Science Evolution: Insights into what it takes to become a data scientist today, emphasizing continuous learning and adaptability. Future of Data Management: The shift towards data and AI operating systems, and Starburst's role in shaping this future. Technology and Technology Partners Mentioned: Starburst, Trino, Apache Iceberg, Teradata, Hadoop, SQL, S3, Azure, Google Cloud Storage, Kafka, Dell, Data Lakehouse, AI, Machine Learning, Big Data, Data Governance, Data Ingestion, Data Management, Capacity Management, Data Security, Compliance, Open Source ☑️ Web: https://www.starburst.io ☑️ Support the Channel: https://ko-fi.com/gtwgt ☑️ Be on #GTwGT: Contact via Twitter @GTwGTPodcast or visit https://www.gtwgt.com ☑️ Subscribe to YouTube: https://www.youtube.com/@GTwGTPodcast?sub_confirmation=1 Check out the full episode on our platforms: YouTube: https://youtu.be/kmB_pjGb5Js Spotify: https://open.spotify.com/episode/2l9aZpvwhWcdmL0lErpUHC?si=x3YOQw_4Sp-vtdjyroMk3Q Apple Podcasts: https://podcasts.apple.com/us/podcast/darknet-diaries-with-jack-rhysider-episode-83/id1519439787?i=1000654665731 Follow Us: Website: https://gtwgt.com Twitter: https://twitter.com/GTwGTPodcast Instagram: https://instagram.com/GTwGTPodcast ☑️ Music: https://www.bensound.com
Summary Data lakehouse architectures have been gaining significant adoption. To accelerate adoption in the enterprise Microsoft has created the Fabric platform, based on their OneLake architecture. In this episode Dipti Borkar shares her experiences working on the product team at Fabric and explains the various use cases for the Fabric service. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst is an end-to-end data lakehouse platform built on Trino, the query engine Apache Iceberg was designed for, with complete support for all table formats including Apache Iceberg, Hive, and Delta Lake. Trusted by teams of all sizes, including Comcast and Doordash. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst (https://www.dataengineeringpodcast.com/starburst) and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. Your host is Tobias Macey and today I'm interviewing Dipti Borkar about her work on Microsoft Fabric and performing analytics on data withou Interview Introduction How did you get involved in the area of data management? Can you describe what Microsoft Fabric is and the story behind it? Data lakes in various forms have been gaining significant popularity as a unified interface to an organization's analytics. What are the motivating factors that you see for that trend? Microsoft has been investing heavily in open source in recent years, and the Fabric platform relies on several open components. What are the benefits of layering on top of existing technologies rather than building a fully custom solution? What are the elements of Fabric that were engineered specifically for the service? What are the most interesting/complicated integration challenges? How has your prior experience with Ahana and Presto informed your current work at Microsoft? AI plays a substantial role in the product. What are the benefits of embedding Copilot into the data engine? What are the challenges in terms of safety and reliability? What are the most interesting, innovative, or unexpected ways that you have seen the Fabric platform used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on data lakes generally, and Fabric specifically? When is Fabric the wrong choice? What do you have planned for the future of data lake analytics? Contact Info LinkedIn (https://www.linkedin.com/in/diptiborkar/) Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today? Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.__init__ (https://www.pythonpodcast.com) covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast (https://www.themachinelearningpodcast.com) helps you go from idea to production with machine learning. Visit the site (https://www.dataengineeringpodcast.com) to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email hosts@dataengineeringpodcast.com (mailto:hosts@dataengineeringpodcast.com) with your story. Links Microsoft Fabric (https://www.microsoft.com/microsoft-fabric) Ahana episode (https://www.dataengineeringpodcast.com/ahana-presto-cloud-data-lake-episode-217) DB2 Distributed (https://www.ibm.com/docs/en/db2/11.5?topic=managers-designing-distributed-databases) Spark (https://spark.apache.org/) Presto (https://prestodb.io/) Azure Data (https://azure.microsoft.com/en-us/products#analytics) MAD Landscape (https://mattturck.com/mad2024/) Podcast Episode (https://www.dataengineeringpodcast.com/mad-landscape-2023-data-infrastructure-episode-369) ML Podcast Episode (https://www.themachinelearningpodcast.com/mad-landscape-2023-ml-ai-episode-21) Tableau (https://www.tableau.com/) dbt (https://www.getdbt.com/) Medallion Architecture (https://dataengineering.wiki/Concepts/Medallion+Architecture) Microsoft Onelake (https://learn.microsoft.com/fabric/onelake/onelake-overview) ORC (https://orc.apache.org/) Parquet (https://parquet.incubator.apache.org) Avro (https://avro.apache.org/) Delta Lake (https://delta.io/) Iceberg (https://iceberg.apache.org/) Podcast Episode (https://www.dataengineeringpodcast.com/iceberg-with-ryan-blue-episode-52/) Hudi (https://hudi.apache.org/) Podcast Episode (https://www.dataengineeringpodcast.com/hudi-streaming-data-lake-episode-209) Hadoop (https://hadoop.apache.org/) PowerBI (https://www.microsoft.com/power-platform/products/power-bi) Podcast Episode (https://www.dataengineeringpodcast.com/power-bi-business-intelligence-episode-154) Velox (https://velox-lib.io/) Gluten (https://gluten.apache.org/) Apache XTable (https://xtable.apache.org/) GraphQL (https://graphql.org/) Formula 1 (https://www.formula1.com/) McLaren (https://www.mclaren.com/) The intro and outro music is from The Hug (http://freemusicarchive.org/music/The_Freak_Fandango_Orchestra/Love_death_and_a_drunken_monkey/04_-_The_Hug) by The Freak Fandango Orchestra (http://freemusicarchive.org/music/The_Freak_Fandango_Orchestra/) / CC BY-SA (http://creativecommons.org/licenses/by-sa/3.0/)

What lessons can product leaders learn from scaling multiple product businesses? In this episode of Product Talk hosted by Sid Shaik, Temporal Technologies Fmr. COO Charles Zedlewski speaks on his career in product management and lessons learned from scaling multiple product businesses. Charles shares insights on becoming a successful PM without a technical background, emphasizing the importance of building technical depth over time. He discusses philosophies for collaborating closely with engineering teams and getting the "soul of the product" to live in their hearts. Charles also talks about his experience scaling Cloudera's Hadoop distribution and lessons from launching new features. Overall, the discussion provides perspectives on product growth strategies, frameworks for conceptualizing customer journeys, and approaches to partnerships between organizations.

S Tomášem a Romanem jsme si povídali o ČSOB, tedy bance, která v Česku spravuje vůbec největší objem peněz ze všech, nabízí služby firemní i retailové klientele a letos oslaví už 60. výročí. Probrali jsme hlavně digitální kanály, od virtuální asistentky Kate přes internetové až po mobilní bankovnictví, ale taky umělou inteligenci, machine learning a související starosti s bezpečností. Kluci totiž musí řešit i to, že se klienti stávají obětí stále sofistikovanějších podvodů

016: Okera Data Management | Amandeep Khurana is CEO & Co-Founder of Cerebro Data. His company works with cloud native data management and governance software for enterprises. Before this he was the Principal Solutions Architect at Cloudera Inc, where he worked with Cloudera's customers to help them with their adoption and usage of the Hadoop ecosystem. *** For Show Notes, Key Points, Contact Info, & Resources Mentioned on this episode visit here: Amandeep Khurana Interview. *** Ready to part ways with your land in Florida? Visit our Sell My Land Florida webpage and discover a straightforward way to say goodbye to your property!

In Elixir Wizards Office Hours Episode 2, "Discovery Discoveries," SmartLogic's Project Manager Alicia Brindisi and VP of Delivery Bri LaVorgna join Elixir Wizards Sundi Myint and Owen Bickford on an exploratory journey through the discovery phase of the software development lifecycle. This episode highlights how collaboration and communication transform the client-project team dynamic into a customized expedition. The goal of discovery is to reveal clear business goals, understand the end user, pinpoint key project objectives, and meticulously document the path forward in a Product Requirements Document (PRD). The discussion emphasizes the importance of fostering transparency, trust, and open communication. Through a mutual exchange of ideas, we are able to create the most tailored, efficient solutions that meet the client's current goals and their vision for the future. Key topics discussed in this episode: Mastering the art of tailored, collaborative discovery Navigating business landscapes and user experiences with empathy Sculpting project objectives and architectural blueprints Continuously capturing discoveries and refining documentation Striking the perfect balance between flexibility and structured processes Steering clear of scope creep while managing expectations Tapping into collective wisdom for ongoing discovery Building and sustaining a foundation of trust and transparency Links mentioned in this episode: https://smartlogic.io/ Follow SmartLogic on social media: https://twitter.com/smartlogic Contact Bri: bri@smartlogic.io What is a PRD? https://en.wikipedia.org/wiki/Productrequirementsdocument Special Guests: Alicia Brindisi and Bri LaVorgna.

Everyone talks about digital transformation, but it seems like no one really explains what it means... until now. In today's episode, Rob and Justin dive deep to cut through the buzzwords and lay out the reality. They're tackling why digital transformation isn't about making huge, instant changes but rather about the smart, subtle tweaks in areas that usually get ignored but badly need a digital lift. They dive into how leveraging tools like the Power Platform can spark significant improvements, showing that it's the small changes that can really boost efficiency and smooth out your workflow. Ever found yourself wondering how to translate all the chatter about digital evolution into actionable steps? That's exactly what Rob and Justin are unpacking. They're guiding you through how minor, yet clever adjustments can transform your processes. It's all about enhancing the routine, one step at a time. And, as always, if you enjoyed the episode, be sure to leave us a review on your favorite podcast platform to help new listeners find us. EPISODE TRANSCRIPT: Rob Collie (00:00): Hello, friends. In today's episode, Justin and I demystify what is meant by the phrase digital transformation. Phrases like that are one of my least favorite things. Why do I say that? Well, these are phrases that get used a lot. They cast a big shadow. You encounter them almost anywhere you go. That's fine by itself. But in the case of digital transformation, that massive shadow is multiplied by no one understanding what it actually means. (00:30): Now earlier in my career, I used to be really intimidated by things like this. Everyone seems to know what this means because they're using it all the time. I don't know what it means, so should I just pretend and play along like everyone else? But at some point, many years ago, I had this moment where I realized that the Emperor has no clothes. It almost never has clothes. Now when I encounter phrases like this, instead of being like paralyzed or intimidated, I instead start working in my own definition and this process takes time. I've been picking apart and stewing on the definition of digital transformation now for probably the better part of a year plus. Somewhere along the way in that process, I realized that we at P3 are doing quite a bit of digital transformation work, I just hadn't realized it yet because I didn't have a good enough definition. (01:18): Lately, I've been noticing that my definition for digital transformation has reached a steady state. It's not changing over time anymore, which tends to be my signal that I've arrived at a definition that works. Now seemed like a good time to sit down and compare notes with Justin, who's been following his own parallel process of arriving at a definition. I'm very pleased with where we landed. A practical and specific definition that can be reduced to practice with an almost paint-by-numbers type of approach. (01:47): If you asked someone for a definition of something like digital transformation, and by the time they're done giving you their definition, you can't practically boil that down to what it means for you, that's not a problem with you, that's a problem with the definition. A lot of times, people's definitions for terms like this are almost like deliberately vague, as a means of projecting power, as a means of actually controlling you. You'll get a lot of definitions that are engineered to sound smart, engineered to sound authoritative, but not engineered to provide anything resembling clarity. Because if you sound smart, and you sound authoritative but you leave your audience hungry, you create a feeling of dependency. Folks, I just think that's yucky. That's just gross. (02:35): To show you what I mean, I just ran the Google search, "What does digital transformation mean?" The very top hit, enterprisersproject.com, defines digital transformation as "the integration of digital technology into all areas of a business resulting in fundamental changes to help businesses operate in how they deliver value to customers." Did that clear it up? Nope. Boiling that one down, it sounds a lot like you should use computers and use them to make changes. But it sounds smart, sounds authoritative. (03:06): Here's the second result from our old favorite, McKinsey. McKinsey defines digital transformation as "the process of developing organizational and technology based capabilities that allow a company to continuously improve its customer experience and lower its unit costs, and over time sustain a competitive advantage." All right, so that one sounds like McKinsey is almost starting with that original definition and adding additional value to it. They're saying use computers to improve, and to make money, and to compete. If you have $1 million to spend, you can get advice like that. (03:43): All right, with those two definitions, we don't even need an episode. We can just skip it? Because everyone knows exactly what they're talking about. These are the top two hits on Google, folks. Useless. Part of the reason these definitions are useless, again, is because they're designed to be useless. But I also think though, that a lot of times you hear definitions like this is because the people writing them actually cannot boil them down. By the time you come up with a truly useful definition, or a framework, or a guide for understanding a topic like this, it almost by its definition, it's not going to sound nearly as sexy, nearly as smart. It's going to sound relatively simple, mundane. But those are the valuable definitions, the ones that we can actually apply, that make a difference in how we actually view our own business. (04:29): That's what we set out to do in this episode. I think we succeeded, came up with a very practical, applicable definition that you'll never find on McKinsey's website. Let's get into it. Speaker 2 (04:42): Ladies and gentlemen, may I have your attention please? Speaker 4 (04:46): This is the Raw Data by P3 Adaptive Podcast, with your host, Rob Collie, and your cohost, Justin Mannhardt. Find out what the experts at P3 Adaptive can do for your business. Just go to p3adaptive.com. Raw Data by P3 Adaptive is data with the human element. Rob Collie (05:12): Justin, one of the things that we really like to do, I really like to do, I think you do as well, is to take a phrase or topic, and demystify it. Especially phrases that you hear repeated over, and over, and over again, and everyone has to pretend that they understand what they mean. But even when they do, they often have very different pictures in their heads. (05:33): One that I think is due for a treatment, and we've hinted at it once before on this podcast but not with any depth, is digital transformation. What does it mean? Justin Mannhardt (05:45): What does it mean, what does it not mean, all parts in between. Rob Collie (05:50): Starting with the places where I hear it. I often hear it in the context of this is something that's already done. The big talking head analysts at places like Gartner- Justin Mannhardt (06:00): Yeah. Rob Collie (06:00): Will talk about it like it's in the rearview mirror. "The shift to digital, the pivot to digital has forced the following things," so has forced, it's a past tense thing. Which further underlines the idea that well, if it's already happened, clearly everyone knows what it means. They don't stop to define it, they're just tossing that aside as a means of getting to the next point. I find that to be one of the most troubling habits of the talking heads. (06:28): The first few times I encountered this phrase, I didn't really know what it meant. I imagined that it meant switching to ecommerce from brick-and-mortar. Justin Mannhardt (06:37): Yeah. Rob Collie (06:37): I didn't even realize that that was the impression I had, it was just this vague feeling in the back of my head. Justin Mannhardt (06:42): The word digital, I'm just thinking about this now because a lot of times, you'll look at one of these diagrams, it's like, "Your digital transformation wheel includes all these things." You'll see something like, "Move to the cloud." I'm like, "Okay, were the servers with the software, was that software analog or something?" Rob Collie (06:59): Yeah, we've been digital for a long time, right? Justin Mannhardt (07:01): Yeah. Rob Collie (07:01): Most broadly defined, you could say that the digital transformation really got going with the adoption of the PC. Justin Mannhardt (07:09): Right. Rob Collie (07:10): That was when digital transformation started. In the sense that it started in the 1980s, maybe it is something worth talking about somewhat in the rearview mirror, but that's not what they mean. They don't mean the adoption of the PC. Justin Mannhardt (07:23): No. But it's interesting, when you think about the timeline of technology evolution. People say, "Oh, you described it as past tense." Digital transformation has occurred in en masse in market. Now today, it's like AI is here, en masse in market. But the pace at which new things are coming out, what's really happening is just the long tail is longer back to where companies were at in this journey. It's not like the entire industrial complex has been collectively moving to the modern current state across the board. There's companies that are still running SQL 2000, that's their production world still. This isn't something that's happened. Rob Collie (08:09): I think that the big talking head analysts often tend to really only talk about the most elite sub-strata of even their own clients. When they talk about this as something that's completely done, even most of Gartner's paying clients, I would suspect, aren't anywhere close to done. But we still haven't really started talking about what it actually means. (08:32): Let's say it is not the switch from paper and pencil systems to electronic line-of-business systems. Not only do we have the PC, and that's been long since mainstreamed, the notion of line-of-business software, server based software, whether cloud or otherwise, line-of-business software is also I think incredibly well entrenched. We're done with having key business systems running in a manual format. That's long since rearview. That also isn't what they mean by digital transformation. (09:07): Of course, both of those are digital and they were huge transformations, but that's not the digital transformation we're talking about. It's anything that's happened after that. Justin Mannhardt (09:15): Yeah. Rob Collie (09:16): It's a lot harder to pin down the things that happened after that. Justin Mannhardt (09:20): In general, I agree with you because the big blocks, software, the availability of the cloud, not having intensive paper process in most companies, that's largely been accomplished. To different levels, of course. Then, what's left? What's the definition? What are we trying to do? Rob Collie (09:41): Well, if you think of the line-of-business application and the PC, the PC interfaces with all the line-of-business apps. I would say that, and even this is not 100% true, but I would say that the conversion to digital systems is complete, or complete-ish. Justin Mannhardt (09:59): Okay. Rob Collie (09:59): When you look at your business as individual silos. Justin Mannhardt (10:03): Say more. You've got a digital environment for finance, digital environment for sales, is that what you mean? Rob Collie (10:09): Yeah. Core workflows have largely been digital for a while. All the workflows that take place between systems, or the workflows that take place adjacent to a system, those are the things that we're talking about when we talk about digital transformation, going after those workflows. (10:30): Everything we've been doing in the world of business software since at least the 1980s has been digital transformation. Justin Mannhardt (10:38): Yeah. Rob Collie (10:39): But our digital transformation, we're really talking about at least the third chapter. It's not chapter one or two. It's like the next frontier, identifying and going after a new class of workflows that would benefit from essentially software support. Justin Mannhardt (10:56): Right. Rob Collie (10:56): Okay. Now because almost by definition, just by subtraction ... We're saying, "Look, we've got the PC, we've got the line-of-business systems that handle the core workflows within a silo. What's left?" Well, it's almost like a perfect mathematical proof. What's left is the stuff between and outside. (11:14): Given that everyone's mix of line-of-business systems is, I like to say, best of breed, meaning random. It's whatever we decided at the time. It seemed like a good idea at the time. Legacy. Justin Mannhardt (11:25): Yeah. Rob Collie (11:26): You're never going to have anything off-the-shelf that helps you solve the workflows. The middleware problem between your systems is always going to be a custom solution. (11:38): We should give examples of these. When I said outside or adjacent to, there's even workflows that they're not really between systems, they're just the offline portion of working with the system. I'm thinking about a budgeting process, for instance. The world's first budgeting systems were mostly there to record your budget that you enter into it. As those budgeting systems have gotten better, they've included more and more of the human workflow that goes into creating, and evaluating, and kicking the tires before it's finalized. Those offline human workflows, getting more and more structured about them, can make a huge difference. Justin Mannhardt (12:19): Not just structured, Rob, more tightly integrated with the adjacent system itself. I like that adjacency, because if you have a financial system where your budget or your forecast lives, there's a martialing of activity, analysis, input. Then you say, "Okay, we need to get it look like this," and then we put it in the thing. What happens in that processes, you get all sorts of scattered iterations of ideas and it gets loose. But if you could have all that iteration tight, the final submission is already handled or much easier. Rob Collie (12:51): Yeah. Sticking with the budgeting example for a moment, it still echoes one of the themes I mentioned for the between systems, the between silos case. Which is that one-size-fits-all systems, off-the-shelf systems, they really struggle to address all the nuances of your particular business. It's very, very difficult. The more, and more, and more you try to get the offline processes, the human processes brought into the digital workflow, the more an off-the-shelf software package is going to struggle. It's getting further and further away from the safety of the core of the task. (13:28): This is why the Power Platform approach to budgeting and planning is often, in fact almost always, a more effective, in terms of cost-effective, time effective, results effective. The core libraries for doing all of the things that you need to do are basically already there and it's inherently designed to be customizable. Justin Mannhardt (13:48): And very nimble. Even the big players in FP&A software, they're not that great, in our opinion, at the end of the day. But the price points just exclude anybody that's not a very sizeable, formidable company. You're not looking to spend that kind of money if you're even a few hundred million a year type operation. You're just not going to sign up to that agreement. You are left with a middleware type of a problem, that you're either solving with spreadsheets, pen and paper, or something else. Our platform can slide right in there. Rob Collie (14:26): Of course, there is a huge advantage to performing a "digital transformation" on a process like that because the human, offline, pen and paper, sending random emails, getting answers, tracking them, it's incredibly tedious, it's incredibly error-prone. Just super, super slow. It's not like you can perform many iterations. You're not even really going to be able to pull off one iteration and you call it good. But you're just going to miss so much. The budget could have been so much better. If you've got a bad budget, of course you're going to pay for that later. (14:58): That's the adjacent case. Let's talk about the between a little bit as well. What's an example of a workflow that would span across different line-of-business systems but require a human being essentially, or humans, to essentially carry the buckets of water between those different pipes? Justin Mannhardt (15:18): We'll make up a company today, Rob, we'll start a new company and it's going to be called I Manufacture Things, Inc. Hey. At I Manufacture Things, Inc., I've got a sales team. Rob Collie (15:28): Do we make things other than ink? Justin Mannhardt (15:30): No, that's incorporated. Rob Collie (15:32): Oh, okay. Justin Mannhardt (15:32): We just make things. Rob Collie (15:34): Can't help it. Can we be We Manufacture Things Ink, Inc.? Justin Mannhardt (15:38): Sure. Rob Collie (15:39): All right. But anyway, we manufacture things. Justin Mannhardt (15:41): There you go. We've got a sales team and they're using a CRM system, such as Salesforce, or HubSpot, or whatever. They're out there, they're doing quotes, they're tracking opportunities, and eventually someone says, "Yeah, I'd love to buy a palette of ink," or whatever. Our company, we're not using the CRM to deal with the production and fulfillment of that order. Okay, so now there's this process where my order form, let's not use any paper in this example, it's still digital but it lands as a PDF form in someone's email inbox that says, "Hey, Customer Service Rep, here's an order." Oh, okay. Now I'm keying said order into our production system that says, "Go manufacture this thing." Now we need to ship the thing out somewhere, and now we're in our logistics system. (16:33): There's all these little hops between systems. Which technology has become more open, and sure there's things like APIs and code based ways to integrate them, but that's not in range for a lot of companies. That's an example of where you could stitch in these little Power Platform type solutions to just, "Hey, let's map the relevant fields and information from the CRM into the order management system." If there's some blanks that need to get filled in, that's okay. Maybe I'm just starting from a queue of new orders right in the system, and I'm maybe adding three or four pieces to that puzzle instead of all of it. Rob Collie (17:12): Okay. I want to make a global note here. Note that we're talking about this broad topic, digital transformation. We're already way down into very detailed, specific use cases. In my opinion, that's what digital transformation is, it's a collection of all of these individual use cases where things can get faster, more efficient, more accurate. It is the sum of many small things. Each one of them might have tremendous impact. This is the way. (17:46): In this particular example, I've been describing the Power Platform as the world's best middleware for a while now. Even Power BI is middleware. It's beautiful, beautiful, beautiful capability is that it can simultaneously ingest data from multiple different line-of-business silos that have never once talked to each other. The only place that they meet is in a Power BI semantic model. Justin Mannhardt (18:10): Yeah. Rob Collie (18:10): And they play a symphony together that Power BI makes them play. They still have never seen each other, but Power BI is what bridges the gap. Now, Power BI is read-only by itself, it doesn't make changes to any systems. (18:25): In this particular case, it sounds like Power App's and Power Automate's music. Let's just get really tangible here. I know that it's a very specific, but it's a fictional example. But lots of people have almost exactly this problem. Justin Mannhardt (18:39): Yeah. Rob Collie (18:39): Just talk me through what a solution to that particular problem might look like if we implemented it in the Power Platform. How much work, how much elapsed time do you think it would take? Let's dig into this one a little bit. Justin Mannhardt (18:51): If what I want to do is, when we receive an order or close a deal in our CRM, I want that to move some data to another system, let's just say that's assumed. Power Automate can solve this need. Obviously there's a lot of detail, you can look some things up online, or you can email robandjustin@p3adaptive.com and we can trade some ideas here. But there are tons of out-of-the-box connectors, and in those connectors they have what's called a trigger. I could say, "When this happens in Salesforce," for example, "I want to start building a flow." I can say, "Okay, I want these fields, and I want to write them from Salesforce to this destination." Maybe that destination's a database, maybe that destination is another system that Power Automate supports that you can write to. (19:37): It could be just this simple mapping exercise. When this happens over here, grab this data, and create a new record over here in this system. Rob Collie (19:46): Okay. A trigger in this case would look something like, "When a record in Salesforce is marked as a win," we've signed a deal, someone wants to buy a palette of whatever. Then automatically, it wakes up, looks at the record in question that the data associated with the sales win in Salesforce, grabs certain fields out of the Salesforce record, certain pieces of information. Let's keep it simple for a moment, and just pushes them into a simple SQL database or something, that could be stood up in minutes. We don't have to spend a lot of time. Or maybe, we just drop it into OneLake. Justin Mannhardt (20:23): Lots of options there. I think this is a nice little simple example, because when you talk about Power BI, that's a very tangible apparatus. These are the things you set up, and you never really go ... You monitor it of course, but you never really go engage with it. You put the glue in place, and it's magic and it's cool. That's a simple version. (20:44): But sometimes, the data coming from its source is incomplete relative to what it's destination requires to take the next action. In this type of scenario you could either say, "Well okay, once it gets over there, we're just in that system, maybe we're adding to it." But this is where you might insert a Power App into the process. Win a deal in Salesforce that triggers, grab these fields. Let's go ahead and write it over to Dataverse, this is a back end of a Power App, for example. Or a database, or SharePoint, who knows. It depends on what makes sense. (21:18): Now we've got a Power App that maybe has a little work cue that says, "Hey, Rob, you've got new orders." You're either approving them, or you're annotating them with additional information. You're doing the human process, like you were describing before, maybe ensuring some hygiene, completeness, whatever. Then you do something in Power App that says, "Okay, go ahead and kick this down the line from here." Rob Collie (21:40): Yeah. Here's an example. In the CRM system where the sale is being executed, there's probably an address for this customer that is associated with that account, especially if we've done business with them before. But this customer might have many different physical locations. A palette of stuff showing up at the wrong physical location would be a real problem. Justin Mannhardt (22:06): Yeah. Rob Collie (22:08): Even just a sanity check Power App that hits the sales rep back, shows up in their inbox or something, shows up in Teams, somehow there's a cue for them to process these things, where they need to just glance at the order and validate that the shipping address is the right one. Justin Mannhardt (22:28): Yeah. Rob Collie (22:28): Even if that's all it is, that's the only additional piece of information is yes, no, that's the right address. Justin Mannhardt (22:34): Yeah. Or sometimes there's a material that is sold is related to a bill of materials to produce. Maybe there's some choices that need to get made in the manufacturing process, such as what specific raw materials are we going to use for this order? Which machine are we going to produce it on this week? Maybe you're just adding the execution instructions. Rob Collie (22:59): This is interesting because you could stop yourself at this moment and go, "Wait a second. Shouldn't those questions be encoded and implemented into the CRM?" The answer is of course, they could be. But your CRM might not be a nimble place to make those sorts of changes. Justin Mannhardt (23:20): That's right. Rob Collie (23:22): It's also a dangerous thing to be customizing. Justin Mannhardt (23:24): Yes. Rob Collie (23:25): There's a lot of validation and testing that's required. There's a reason why modifying and writing custom code into one's CRM doesn't happen all that frequently. Whereas this process you're describing is relatively safe, by comparison. It doesn't rock the boat. It's between. Forcing these sorts of modifications and customizations into the individual silo line-of-business applications, if that were so feasible, that would already be happening. Justin Mannhardt (23:55): I've worked for companies like this, I've engaged with companies in my consulting career like this, where they have done that. They said, "We've got the talent in-house, so we're going to customize this thing." Then you get into a conversation of, "We'd like to upgrade to the newer version." They realized, "Oh, we can't." Rob Collie (24:18): Yeah. "It'll break out customizations," yes. Justin Mannhardt (24:20): Or sometimes, the programming language that the customizations are done in is not the same programming language in the newer version. While it's possible, if you have the resources, the time, and the money, it becomes a heavier lift. It begs the question, why? Rob Collie (24:36): I was describing the heavy lift being that the original line-of-business system might be resistant to change, resistant to the customizations that you want to implement. You're describing it as also, even if you do perform those customizations, the next major software upgrade is going to be a problem. That rings true for me. I remember the object model in Office- Justin Mannhardt (24:59): Oh, yeah. Rob Collie (25:00): All the VBA solutions that were out there, being incredibly paralyzing in terms of the things we could do with the product, because if you broke people's macros, they wouldn't upgrade to the new version of Office. Justin Mannhardt (25:09): Yeah, been there. Yeah. Rob Collie (25:12): I promise you that, at Microsoft, we took that problem and approached it with a level of discipline that it was probably 10 times greater than the average line-of-business software vendor. Because most line-of-business software vendors see themselves as platform vendors. They want to be considered like that, but they don't want to pay the price of it. So that's good. (25:30): But then, the other thing is is if you built it into the line-of-business system, then inherently you're saying, "Okay, whatever that extra logic is, then it's up to that line-of-business system to then push those records across the wire." The new information has to go from the CRM to the other system. That kind of customization, both ends of the process are going to be very non-cooperative with this. This is another reason why doing this in a lightweight, nimble, intermediate layer provides a shock absorber to the system. Justin Mannhardt (26:08): I like that analogy. Rob Collie (26:09): It's pretty easy for Power Automate, all it's doing is pushing a handful of doing to something and that other something is going to take care of all the validation, all of the retry. Validation with human beings, but also the logging in to the other system and all of that. Coding all of that into your CRM is almost a non-starter. This is why the between workflows have remained so non-digitized. Justin Mannhardt (26:42): Yeah. There's also a lot of tedium should be in play here, too. You have a written process, you look at your SOP documents and you say, "Oh, when this happens, Jan sends an email to Rob." Okay, well we could probably just get the Power Automate to send the email to Rob, if that what needs to happen. (26:59): An example of this is something I built for myself at P3. When a potential new customer reaches out to us, and they want to meet with us and just chat, I wanted a process that reminded myself to go check out who that company is, understand who I'm going to talk. I just had a trigger that said, "When a meeting gets scheduled from this arena, just create a task for me to remember to do this before the meeting." Even little things like that, that are just personally useful, have been really beneficial as well. (27:33): It's much easier to say well yeah, dashboards, charts, graphs, cool. Or even fabric, even though that needs some demystifying still. This middleware, it's invisible, there's so many options. There's 100,000 little improvements you could make with it. Rob Collie (27:48): The world has spent a long time coming around to why dashboards could be valuable. Justin Mannhardt (27:55): They still are. Rob Collie (27:56): Yes. When you say the word dashboards and you show that work product, even in the abstract to someone, the communication of what the value is benefiting from all of that history of the world waking up to the value of dashboards. Honestly, it wasn't that clear 15 years ago. It wasn't clear to people, most people anyway, why they needed them, why they were better than just running the reports out of each line-of-business system. But because it's such an inherently visible work product, it is a lot easier, I'm going to use the word, it's a lot easier to visualize what the impact will be, what it does for you. Whereas these other workflows, until you know that they're improvable, this is why digital transformation is so hard to understand because it is really talking about spaces where it's hard to visualize software helping because it's never been able to help. (28:53): Let's go back to this example where the sale happens in the CRM system. Some information just automatically gets dropped in a data store, off to the side for the moment. There's potentially some Power App clarification. There are human inputs that are required here and you still want a human being to provide those. Justin Mannhardt (29:16): I want to point out here too, it's easy to get into a situation where that data store is simply being read by a report, even a Power BI report. But if the human's going to say, "Yes, no," or add to it, the Power App is just a way better piece to put there. Rob Collie (29:32): Yeah. Let's have this example be like an example that we would look at and smile, be proud of. The Power App is involved. Then when the human interaction is done, they press okay or approve in the Power App. Take me to the next step. Justin Mannhardt (29:49): Well ideally, we are pushing data and information into the next system or workflow. Rob Collie (29:57): This is a two silo problem. We have the CRM system and then we have the manufacturing, work order and shipment system, the fulfillment system. Justin Mannhardt (30:06): The WMS. Rob Collie (30:08): Is that what that is? Justin Mannhardt (30:08): Yeah. Rob Collie (30:09): Okay. We've already covered the first silo. We've gotten the human interaction. Now it's time to send it on to the second silo. How does that work? Justin Mannhardt (30:20): This just comes down to what the point of integration is in the second silo. We could be inserting records into a SQL database, we could be making a post request to an API endpoint. In Power Automate, most of these things are WISIWIG in nature. There is an open code interface if you need to get to that and want to do that, need it. But usually, it's just mapping. You find your destination and it says, "Oh, here's the fields to map to." You say, "Okay," you just drag and drop. It just depends on what your destination system is, but you're just creating a target in your workflow, and the data goes. Rob Collie (30:55): The way I like to look at this is that, even though each line-of-business silo system, they're never really built to talk to each other. Justin Mannhardt (31:04): Right, they need a translator. Rob Collie (31:05): Yeah. The translator and the shock absorber. But at the same time, it's not hard to get the information you want out of one system, and it's not hard to write the information you need into another. But when you try to wire them directly through to each other- Justin Mannhardt (31:23): Yeah. Rob Collie (31:23): That is actually really difficult. You need this referee in the middle, that's able to change gears, like the ambassador between the two systems. When you think about a translator system, an ambassador system, a shock absorber, whatever you want to call it, whatever metaphor you want, you can also imagine an incredibly expensive, elaborate piece of custom software that's being written to do that. That's not what we're talking about. Justin Mannhardt (31:47): No. Rob Collie (31:48): Let's recap. Trigger fires in CRM system, some data gets slurped out related to that sale, dropped in an intermediate location that then powers a Power App. Power App is able to read that information, it knows who to reach back to to get the clarification, the approval, et cetera. It might be multiple people that need to provide some input. Justin Mannhardt (32:09): It could be a whole workflow that lives right there. Rob Collie (32:12): But eventually at the end of that workflow, in this case we'll just assume it's one step, one human being, the sales rep just needs to sign off, then the Power App's job is done. That's the human interaction part. Now we're back to Power Automate, correct? Justin Mannhardt (32:24): That's right. Rob Collie (32:25): Power Automate will notice there's another trigger that the Power App is done with its part, the approval button was pressed. Justin Mannhardt (32:31): Clicked, yeah. Rob Collie (32:33): Then it turns around, and it knows, because again we wire it up ... It sounds like we might be lucky, it's just drag and drop, one time development. But if it's not, it's probably not that much code, to go inject the new work order into the WMS system? Justin Mannhardt (32:52): Yeah, it's the WMS, warehouse management system. Rob Collie (32:53): Let's call that the end of the story for this one integration. Let's say things go incredibly well in this project. We don't really encounter any hiccups. Best case scenario, how long on the calendar would it take for us to wire something like this up? Justin Mannhardt (33:12): Yeah, best case scenario this is something that gets done inside of a week. Rob Collie (33:15): That's the difference. Justin Mannhardt (33:16): Yeah. Rob Collie (33:18): All right. Worst case scenario, both of these systems are more stubborn than usual, the connectors aren't built into the system, and they still have some relatively rudimentary ways of data access, but it's nothing WISIWIG off-the-shelf. We just get unlucky with these two stubborn line-of-business systems. How bad can that be? Justin Mannhardt (33:37): Well, instead of being inside of a week, maybe it's weeks, like two or three. The only reason that gets extended would be okay, instead of pure WISIWIG drag and drop, maybe we are having to do some light handling of adjacent array. But there's tools for that. You can say, "Parse this into fields so I can now drag and drop it." Maybe instead of our Power Automate workflow having three, four steps, maybe there's 10. Some of those steps have a little bit more involvement. Maybe there's some time because we got to troubleshoot a little bit more and make sure we've got it all right. But I think the overall point here is these are relatively light touch on the calendar. Rob Collie (34:18): I had a job in college that I've never brought up on this show. Justin Mannhardt (34:23): Ooh. Rob Collie (34:23): I was obsessed about this workflow for nearly a whole decade afterwards. Where I was working for a construction company, and there's this thing in the construction industry that I'm sure is still a thing, and it's called the submittals process. Where it turns out, when you're going to build a building, there's an ingredients list for a building. You were talking about different material options for manufacturing. So we're going to make a brick exterior. Okay, what kind of brick? There are many different colors, kinds, textures, levels of quality. Literally, the owner of the building, the person paying to have the building built, that owner and their architect, and sometimes their structural engineers, are going to want to hold a physical brick in their hand. Justin Mannhardt (35:05): Right. Rob Collie (35:06): This is the brick that you are going to use. They want to inspect it with their eyes, whatever, they want to feel ... Maybe even run tests on it. Justin Mannhardt (35:14): Smack it with a hammer. Rob Collie (35:16): Right. Then, when you build the building, you better use that brick because they're holding onto the brick, the sample, the reference brick. You think about the number of ingredients that goes into building a building, and the building in question that I was working on helping out with this process was the new chemistry building at Vanderbilt University. It was not just a regular building, it had all kinds of specialized hardware, and exhaust, and crazy stuff that wouldn't be in a normal building. (35:44): There's this long list of materials that need to have submittals produced for them, samples. The requests all go to a million different vendors. You have to ask the subcontractor, the plumbing contractor, what pipe they plan to use. You find out what pipe they plan to use and then you say, "Okay, where do I get a sample of that pipe?" Sometimes you have to send the request for the sample to the pipe manufacturer, or something the subcontracting, the plumber, people will do it for you. Ah! It's awful. (36:14): I was brought in to just be the human shock absorber in this process. I was constantly taking information from one format, copying and pasting it, if I was lucky. Usually, re-hand entering into another one. I have to do this multiple times. I have to do this on the outgoing request, and then the incoming materials coming back. Ugh, and then the shipping labels and everything. It was just they brought me in because they had their assistant project manager for the construction company, the general contractor, on this site. All of this was having to go through him. It turns out, he had another job which was called build the building. Justin Mannhardt (36:54): Just a minor, little job. Rob Collie (36:56): Yeah. The job of push the samples around was a fine thing to subcontract to a college student. I swear, I did 40 hours a week on that for a whole summer, and then part-time for the next two years. That's all I did. Justin Mannhardt (37:13): Make note, students. If you take an internship and you end up like Rob, learn how to do Power Automate stuff and use that for your internship. Rob Collie (37:22): By the way, we already had Lotus Notes with a tremendous amount of customized Lotus Note template for this process. Justin Mannhardt (37:30): Yeah. Rob Collie (37:30): But all that really was was just another line-of-business system that didn't talk to anything. It spit out paper is what it did, it spit out printed slips that announced, "This is your brick." Justin Mannhardt (37:42): Congratulations. Rob Collie (37:44): That would be a really, really challenging digital transformation process today, because not only is it cross system, it's also cross companies. But I'm sure that, if we looked at that process today, we would find things that could be optimized. Justin Mannhardt (37:56): Oh, yeah. Your example reminded me of a really important opportunity in the construction industry or lots of trades. You're talking about people that are out in the field, on job sites, on location, they're not sitting in offices at workstations. All of these things we're talking about, especially these Power App interfaces, can be optimized for mobile. Instead of, "Oh, I'm going to write this down so when I get back to my home office," I can put something on the smartphone. Even if you're not picking from a list of material SKUs or whatever, you can say, "Hey, Rob needs a brick." (38:36): Now this goes back to your central office, and it's into a work queue, and another screen in the Power App, then they can go navigate the vendors and all that sort of stuff, too. That's a great example of where you can just put a little spice on it. Rob Collie (38:50): I said that was the only thing I did in that job, that's not true. I had other jobs. One of them was the plumbing contractor was deemed to be running well behind schedule, they were not installing pipe fast enough, pipe and duct work. They assigned me, the construction company assigned me the job of going out there, walking through the building and seeing how much had been installed, linear feet of various materials, and writing it down. I was terrible at this. It's not a good fit for me at any age, but at age 20, I was just constantly under-reporting how much work they'd actually done and getting them in trouble. Justin Mannhardt (39:32): This does not sound like a good use of Rob. Rob Collie (39:34): Eventually, everyone bought me the little thing that wheels along on the ground and counts distance. What I would do is I'd be looking overhead at these copper pipes that were hanging from the ceiling, and I'd just stand beneath one end of them and walk across the building, tick, tick, tick, tick, tick, tick. But then, what would I do? I would write it down. I'd write down a number. What floor am I on? What side of the building am I on? Which pipes am I looking at? "Oh yeah, 150 linear feet." By the way, have I already counted those pipes? Did I count those pipes last week? I don't know. Justin Mannhardt (40:11): There's errors in the world that have Rob Collie's fingerprints on them. There's a building somewhere that's had some pretty serious issues over the years and it's Rob's fault. Rob Collie (40:21): The plumbing contractor had a pretty good sense of humor about it. They knew I was a youngster. Anyway, really just another example of something that could be digitally transformed today and it doesn't have to be difficult. (40:33): This is not something that's a global, let's go digitally transform the whole company all at once. You can pick and choose some high value examples. And decide if that's a sufficient win for you, you might be encouraged to do it elsewhere. There's no thou shalt do all of these things, there's nothing like that. You get to choose where your cost benefit curve lies. But just even knowing that this is possible I think and what it entails. Demystifying ... The process we just walked through, with today's technology, is not difficult. We're talking, as you said, within a week to several weeks on the worst case end. You do realize a bunch of benefits from that. Justin Mannhardt (41:16): Yeah. I love how well the Power Platform, and this idea of it being middleware, just leans right into an idea that's been around for a long time in companies, which is continuous improvement. You can look at a problem, like the ones we've been describing, and you can go down the path and you say, "Okay, is there a piece of software that would solve or improve this problem?" You could look into something like that. Or you could say, "Actually, we have these other tools that we've been learning how to use and integrate into our organization, and we'll just take a week, or three weeks and make it better." If you decide to replace a silo down the road, like, "Hey, we're going to do a CRM take out," you've not saddled yourself up with this huge level of tech debt. Rob Collie (42:05): Yeah, that's huge. Justin Mannhardt (42:06): Because a lot of these decisions have so much pressure because you're like, "If we don't get this right, then we'll have all this." It's actually okay to be like, "Yeah, we're going to throw this away and build a different one." I think that's an important aspect of these things. You can empower a team of people who are just interested in making things better and it's not this huge sunk cost or investment that you're never going to get back. You're going to get value from it, even if you're only going to leverage it, say for a year. It's like, "Hey, that week was worth it because it eliminated this many errors," or lost time, or whatever. Then we did something else. Rob Collie (42:44): This really hearkens back to something that I struggled to explain to people in my time at Microsoft. I had an intuition, and a lot of people had the same intuition, we weren't doing a great job of explaining it. What I'm going to talk about is the XML revolution. (43:01): XML, and JSON, and all these sorts of things, are just taken for granted today. There's nothing magic about them, it's completely commoditized and that's the way it should be. But those of us who saw this XML thing coming as a real game changer, I think we're really just keying in on exactly this thing we're talking about. The world had been obsessed with APIs up until that point. Every system had an API on it that was capable of doing verby things. Read/write, make changes. These APIs tended to be very heavy. Anyone that's ever written any macro code against Excel will know that the Excel API is incredibly complicated. I'm talking about the desktop VBA comm automation. Go play around with the range object for a couple of days. (43:49): The idea that two systems with good APIs could then talk to each other was still this myth that I think most of the software world believed. Our belief was stubbornly that we just hadn't gotten the APIs right yet. The next standard in API was going to get it done. What XML did, all it was really doing was saying, "Look, there's going to be a data transmission format that is completely separate from any API, and it's super, super readable, and it's super, super simple." It's the beginning of this shock absorber mentality. Since then, we've discovered that it doesn't have to be XML. Justin Mannhardt (44:30): Oh, yeah. Rob Collie (44:31): But the XML thing did eventually lead us down the road of Hadoop, and DataLakes, and all of that. But yeah, this notion that you get the necessary data from system one, and there's this temporary ah, breath that you can take, and you can disconnect the process of slurp from system one and inject new into the other system. You can ever so slightly disconnect those two so they're not talking directly to each other. When you do that, you gain just massive, massive, massive benefits. (45:03): Yeah, it's kind of neat to connect that now. Again, I used to talk to people all the time like, "No, XML is magic. It's going to blah, blah, blah." People would go, like my old boss did, again would be like, "I don't get it. Why is it magic?" I'd be like, "Well, it just is, man. You don't understand." He beat that out of me. It was one of the greatest that anyone's ever given me. By the time I was done with him, I could explain why XML was valuable but not at the beginning. I certainly didn't envision where we've landed here. (45:27): Okay, so I think this was pretty straightforward, right? If you want to identify what digital transformation means for your organization ... This actually really parallels the talk I gave on AI the other night here in Indy. Justin Mannhardt (45:39): Oh, right. Yeah. Rob Collie (45:40): Don't talk about it from the tech point of view. Justin Mannhardt (45:43): Yeah. Rob Collie (45:43): Think about it from the workflow point of view. Where are the workflows in your company? What's really beautiful about digital transformation is that we can provide this extra guidance that, what are the workflows that happen between systems or adjacent to systems? Justin Mannhardt (46:00): Yeah. Rob Collie (46:00): It helps you focus on what we're talking about. It's not often you get a cheat code like that, so you can really zero in on something. (46:08): I suspect that once you have that algorithm for looking, you're going to find lots of things. The Power Platform makes it- Justin Mannhardt (46:18): Ah, it transforms them in digital ways. Rob Collie (46:20): It puts that completely within range, completely within budget in a way that you wouldn't necessarily even expect. It's just kind of magic. It's the same level of magic that you'd get from Power BI, but in a read/write workflow sense. Justin Mannhardt (46:33): Between and adjacent to, that's magic. That's a magic algorithm because I bet a lot of people, when you say digital transformation, they are thinking on or within the system, not between it. Rob Collie (46:45): Yeah. It's another one of these marketing terms that's almost deliberately meant to be mystical. Everyone's supposed to pretend that they know what it means, but then it's left for all of us out here in the real world, close to where the rubber meets the road, to actually do something real with it. (46:59): I wonder what percentage of the time people use the phrase digital transformation, if you scratch the surface, you'd find that they were completely bluffing? Justin Mannhardt (47:07): Yeah. There's a category of thinking digital transformation, or even data analytics, where there's just all these abstract, conceptual statements or diagrams that mean very little. Let's just zoom into an actual problem, even if it's a little one, and fix it. Then, we'll go to the next one and fix that. We don't need big, fancy frameworks, teams, and steering committees to do any of that. Rob Collie (47:35): I've got another example. Justin Mannhardt (47:36): Oh, yeah? Rob Collie (47:37): It's one that we've implemented here at P3. We have these Power BI dashboards that measure the effectiveness of our advertising. It turns out that advertising in particular on Google AdWords is not a global thing. It's the sum of many micro trends, your overall performance. It's highly, highly, highly variable based on which keywords you're matching against, what kinds of searches you're matching against, and what kind of messaging you're presenting to the user of Google. The only way to improve, most of the time, is to improve in the details. (48:11): All right. For a while, we had this workflow where we'd identify an intersection of ads that we were running and what we were matching up with, in terms of people's searches. We'd identify a cluster of those that, I'll just keep it simple for the moment, where we'd say, "Look, right now we're providing the same message to a bunch of searches that aren't really the same search and we need to break this out, and provide a more custom, tailored message to each of these individual searches." We'd mark something for granularization. (48:43): But originally, what we would do is we were looking at this report, we'd write down essentially this intersection and say, "Go split that out." Justin Mannhardt (48:51): What did we do? Rob Collie (48:52): Immediately, we'd lose all track of what did we even decide to do? Because then someone had to go over to totally Google AdWords system and enter new ads, and break this thing out. Even knowing whether that had happened, producing the work list of things that needed to happen, was very difficult because we were in the context of a Power BI dashboard that didn't do any communication elsewhere. We couldn't track what our to-do list was. Except again, completely offline. We built a Power App and embedded it into some of these reports. You'd click on the thing you'd want to break out, the Power App would pick up that context, and then we'd just use a little drop-down and say, "What do we want to do to this?" We're going to mark this for granularization. (49:39): That did produce us a to-do list, that then could also be re-imported back into the report, so that we could se that we had marked that one to explode it out. We didn't have to look at it again, and we also in the reporting, could see whether that splitting up had been done because you'd come back to the Power App and say, "Done." Even better, you'd enter the IDs of the new groups, so that you can say, "Hey, this one is now superseded by these." (50:07): Now we never got to the point of directly writing back to Google AdWords to make the changes. That still happened offline. We certainly could have imagined a world in which a Power App, a much more elaborate process was built that, then separately from the dashboard, would prompt you to write the new ad copy and things like that. You get to choose where the 80/20 is in your process. For us, the 80/20 was recording the list and tracking the lineage while we're in the context of the report. That was a big deal. Justin Mannhardt (50:39): There are over 1000 pre-built and certified connectors available for the Power Platform. Rob Collie (50:46): That's it? Just kidding. Justin Mannhardt (50:48): They're adding things all the time. We live in a SaaS world. All these things, they're real. Rob Collie (50:53): Yeah. That's a really critical point about Microsoft, is that they have realized that they are the middleware company. Justin Mannhardt (50:59): Satya is all about it. Rob Collie (51:00): Yes. In the Bill and Steve era, this was not Microsoft's game. They wanted to own everything. Justin Mannhardt (51:06): Yeah. Rob Collie (51:07): In Satya era, it's more like, "No, we want to work with everything." Justin Mannhardt (51:11): It's great, I love it. Rob Collie (51:12): Just recently, as I've gone down this path myself, reverse engineering in my own little way what this term means and coming to the conclusions that we have, I've realized that we are a digital transformation company. It's not the only thing that we do. Is read only Power BI middleware, is that digital transformation? Well, probably. By the strictest definition, probably yes, but not by the spirit of the law. The spirit of the definition means a read/write workflow. I'd mentioned in this last example, Power BI can be part of a read/write workflow. There's no reason to sideline it. In the other episodes, where we talked about improvement and action is the goal, how a Power App can be added to a Power BI report to help you take action on what the report is telling you. But just the broader Power Platform, Power Apps and Power Automate in particular. We do have a handful of clients where, most of the work we're doing is digital transformation work. Justin Mannhardt (52:08): Right, this type of work. Rob Collie (52:09): The adjacent in between that we're talking about. Even though we're mostly thought of as a Power BI company, as we're doing our next round of website rebuild, we've 100% put a digital transformation page on our sitemap. It'll probably use some of this language we're talking about here. Digital transformation, what does it mean? It is both not that special of a term, there's no rocket science to it, and at the same time, there's a lot of value to be realized from it. Justin Mannhardt (52:36): Totally. Here's a fun little call back to our origin story as individuals and as a company. We spend a lot of our time helping, for example, like the Excel analyst move over to Power BI and we're trying to solve these middleware gaps. That's why I think, for us, it's just been quite natural to provide these types of services and capabilities to customers as we've grown because it's the same type of person that's spirited to solve these types of issues, and the technology, and the openness of it brought everything in range. It's fun to reflect back on how broad we can show up to a customer beyond just dashboards. Rob Collie (53:22): Yeah. It's a miracle and a testament to what Microsoft has pulled off. You can certainly imagine a world in which they could enable that uptempo, highly efficient, what we call faucets first methodology for dashboards. Justin Mannhardt (53:22): Yeah. Rob Collie (53:38): And stopping there. To extend it to something like workflow and applications, and have implementation of these solutions feel very, very, very similar. Justin Mannhardt (53:50): Yeah. Rob Collie (53:50): It's completely compatible with our ethos. It's almost like I didn't even notice when we made that transition into doing both. It sneaked up on me. That's a good sign. I feel a little silly that it took me a while to digest it, but I love that it happened organically without us having to go- Justin Mannhardt (54:10): Right. Rob Collie (54:11): Pick up another toolset from another vendor, or change our hiring profile dramatically, or anything like that. Justin Mannhardt (54:18): Yeah. Now, we've got some of these cool projects where you've got maybe someone that their expertise is more on the Power BI side, working right alongside someone whose expertise is more on the Power Apps, Power Automate side. They're just moving in lockstep with the same customer, closing these middleware gaps, building the reporting, and the action lives around it. It's that whole thing working together that makes it all really cool. Rob Collie (54:41): I'm also developing an intuition that AI, maybe not the only application of AI, but I think a lot of the surface area of where we will find AI to be useful, plugs into this digital transformation thing, the adjacent in between. In particular, in sub workflows within the overall workflow. Justin Mannhardt (55:03): Yes. Rob Collie (55:03): Did your reaction fit that? Justin Mannhardt (55:06): Yes, totally. Totally, totally, totally. Yeah. Rob Collie (55:09): Then, we're good. I think it's easy, with dashboards, with BI, to imagine the global. Going from a non-dashboard company to a dashboard company, it's very easy to imagine that as a global thing and it's probably the right thing. Any place where you're flying without the information you need in a convenient, easy to digest format, let's go and get that. Even there, with the transformation to a data oriented organization, a data driven culture, you still pick places to start. Justin Mannhardt (55:39): You got to start somewhere. Rob Collie (55:40): This other thing, digital transformation is a little harder to imagine is a global thing, and that's fine. I think AI's the same way. You should not be thinking about AI as a global transformation for your business. Just like digital transformation, it is a go find particular places where you can score these wins. Speaker 4 (56:00): Thanks for listening to the Raw Data by P3 Adaptive Podcast. Let the experts at P3 Adaptive help your business. Just go to p3adaptive.com. Have a data day.
Summary A core differentiator of Dagster in the ecosystem of data orchestration is their focus on software defined assets as a means of building declarative workflows. With their launch of Dagster+ as the redesigned commercial companion to the open source project they are investing in that capability with a suite of new features. In this episode Pete Hunt, CEO of Dagster labs, outlines these new capabilities, how they reduce the burden on data teams, and the increased collaboration that they enable across teams and business units. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and data pipelines. It is an open-source, cloud-native orchestrator for the whole development lifecycle, with integrated lineage and observability, a declarative programming model, and best-in-class testability. Your team can get up and running in minutes thanks to Dagster Cloud, an enterprise-class hosted solution that offers serverless and hybrid deployments, enhanced security, and on-demand ephemeral test deployments. Go to dataengineeringpodcast.com/dagster (https://www.dataengineeringpodcast.com/dagster) today to get started. Your first 30 days are free! Data lakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics. Trusted by teams of all sizes, including Comcast and Doordash, Starburst is a data lake analytics platform that delivers the adaptability and flexibility a lakehouse ecosystem promises. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Want to see Starburst in action? Go to dataengineeringpodcast.com/starburst (https://www.dataengineeringpodcast.com/starburst) and get $500 in credits to try Starburst Galaxy today, the easiest and fastest way to get started using Trino. Your host is Tobias Macey and today I'm interviewing Pete Hunt about how the launch of Dagster+ will level up your data platform and orchestrate across language platforms Interview Introduction How did you get involved in the area of data management? Can you describe what the focus of Dagster+ is and the story behind it? What problems are you trying to solve with Dagster+? What are the notable enhancements beyond the Dagster Core project that this updated platform provides? How is it different from the current Dagster Cloud product? In the launch announcement you tease new capabilities that would be great to explore in turns: Make data a team sport, enabling data teams across the organization Deliver reliable, high quality data the organization can trust Observe and manage data platform costs Master the heterogeneous collection of technologies—both traditional and Modern Data Stack What are the business/product goals that you are focused on improving with the launch of Dagster+ What are the most interesting, innovative, or unexpected ways that you have seen Dagster used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on the design and launch of Dagster+? When is Dagster+ the wrong choice? What do you have planned for the future of Dagster/Dagster Cloud/Dagster+? Contact Info Twitter (https://twitter.com/floydophone) LinkedIn (https://linkedin.com/in/pwhunt) Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today? Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.__init__ (https://www.pythonpodcast.com) covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast (https://www.themachinelearningpodcast.com) helps you go from idea to production with machine learning. Visit the site (https://www.dataengineeringpodcast.com) to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email hosts@dataengineeringpodcast.com (mailto:hosts@dataengineeringpodcast.com)) with your story. Links Dagster (https://dagster.io/) Podcast Episode (https://www.dataengineeringpodcast.com/dagster-data-applications-episode-104) Dagster+ Launch Event (https://dagster.io/events/dagster-plus-launch-event) Hadoop (https://hadoop.apache.org/) MapReduce (https://en.wikipedia.org/wiki/MapReduce) Pydantic (https://docs.pydantic.dev/latest/) Software Defined Assets (https://docs.dagster.io/concepts/assets/software-defined-assets) Dagster Insights (https://docs.dagster.io/dagster-cloud/insights) Dagster Pipes (https://docs.dagster.io/guides/dagster-pipes) Conway's Law (https://en.wikipedia.org/wiki/Conway%27s_law) Data Mesh (https://www.datamesh-architecture.com/) Dagster Code Locations (https://docs.dagster.io/concepts/code-locations) Dagster Asset Checks (https://docs.dagster.io/concepts/assets/asset-checks) Dave & Buster's (https://www.daveandbusters.com/us/en/home) SQLMesh (https://sqlmesh.readthedocs.io/en/latest/) Podcast Episode (https://www.dataengineeringpodcast.com/sqlmesh-open-source-dataops-episode-380) SDF (https://www.sdf.com/) Malloy (https://www.malloydata.dev/) The intro and outro music is from The Hug (http://freemusicarchive.org/music/The_Freak_Fandango_Orchestra/Love_death_and_a_drunken_monkey/04_-_The_Hug) by The Freak Fandango Orchestra (http://freemusicarchive.org/music/The_Freak_Fandango_Orchestra/) / CC BY-SA (http://creativecommons.org/licenses/by-sa/3.0/)

It's easy to get technical when you're writing copy about a highly technical subject. But that's when you lose your audience.Instead ask, "What problem is this solving for my customer?" And explain it in their language.That's one strategy inspired by Michael Crichton that we're exploring today with the CMO of Promo.com, Joel Horwitz. Together, we talk about writing in layman's terms, thoroughly researching the problem you're trying to solve, and learning something new about marketing every day.About our guest, Joel HorwitzJoel is an experienced High-Tech Marketing professional with a diverse background in data science & engineering, product strategy and digital marketing. Prior to Promo.com, he was the Chief Marketing Officer of AudioEye where he led the Go-To-Market team with a Product-Led Growth Strategy that helped grow the company from less than 300 customers to over 30,000 in a year. Prior to that, at IBM, he championed the value of a Digital Go-To-Market as the Global Vice President of Strategic Partnerships and Digital Offerings for IBM's Digital Business Group. In addition, his extensive background in Data + AI has helped him lead breakthrough customer experiences including the AudioEye Accessibility Solution, IBM Data Science Experience, Alpine Data Labs Modeler, Datameer Sheets for Hadoop, H2O.ai Sparkling Water, and more; through the introduction of platform partnerships, self-service offerings, and digital go-to-market.Joel holds an MBA in International Business from the University of Pittsburgh, an MS and BS in Nanotechnology from the College of Engineering at the University of Washington, Seattle, WA. He is a board member of NUMFocus, an advisor to a number of startups, and a volunteer in his local community. About Promo.comOriginally launched in 2016 as a B2B video creation and distribution platform, Promo.com has since won numerous awards, scored top customer reviews and has been deployed by Fortune 500 companies for social media marketing purposes for 10,000+ Brands. Promo.com's latest product, PromoAI Copilot, soft-launched in October 2023, gaining over 1,000 customers who are now using the Promo.com Platform. Its latest product, PromoAI Copilot is now available at Promo.com or on the OpenAI GPT Store.About Michael CrichtonMichael Crichton is the late award-winning author, screenwriter and filmmaker, having passed away in 2008. He's most known for having written Jurassic Park and having created ER. He was incredibly prolific. So he's also known for books, movies and TV shows like The Andromeda Strain, The Lost World, Westworld, and all the other Jurassic movies (Jurassic Park III, Jurassic World, etc.) He also wrote frequently under the pseudonym John Lange of Jeffery Hudson. He has sold 200 million books, and his books have been translated into 38 languages, and 13 of them have been made into movies. He has an Emmy and a Peabody among other awards.What B2B Companies Can Learn From Michael Crichton:Write in layman's terms. Even when it's a highly technical product or concept, write so the general reader can understand your topic. Joel says, “What makes Michael Crichton remarkable is his ability to explain highly complex and difficult ideas in a way that a nine year old can understand them. If you're in the high tech industry, you're working with cryptocurrencies, blockchain, artificial intelligence, machine learning, or large language models. All this stuff is very difficult to understand if you're a novice. So if you can communicate these ideas and not just explain them for what they are, but then to try to compel somebody to be interested in these ideas and then extrapolate a whole story and a whole vision of where this could take us, that to me is Remarkable.”Thoroughly research the problem you're trying to solve. Become an expert on the topic and then teach your audience about it. Explaining how your product solves the problem in detail and backing it up with research builds credibility as well as drives engagement and conversion. Joel says, “Ultimately, marketers are teachers. What are we really doing with content marketing? We're teaching people about how to think about a particular product area. A lot of the work goes into really making sure you've got the problem right that you need to solve. Not as much on the solutioning side. Usually it's like, ‘What is the problem that we're trying to actually solve here?' And researching that.” And he adds, “Not just reading, but actually, for example, going to the location or going out and actually talking to customers.”Learn something new about marketing every day. Ask questions and be intensely curious. Learn from your peers, from Google searches, or subscribe to a newsletter like Harry Dry's, Devin Reed's or Emily Kramer's. Joel says, “Constantly be learning, coming into things with a beginner's mindset. I think that's another big thing Michael Crichton does well. He asks a lot of good questions. My grandfather told me the smartest men and women ask the best questions. They act as if you don't know something because that's how you learn.”Quotes*”I was never one for the big unveil. I've always been like, ‘All right, what are the things that we can incrementally change and test to see if we're moving things in the right direction?'” - Joel Horwitz*”I think we often think of, ‘Who's that one ideal customer profile or who's that one champion that we need to target?' But these decisions, especially B2B, they're never made by a single person. It's almost always a team. And so it's really helpful for me to think about, ‘Who are the different personalities in the room that I'm speaking to?' Because I think if you can convince them or they can all see kind of their own story, their own journey, and how this product or how the solution is going to help them, I think you have a much better chance of getting their attention.” - Joel HorwitzTime Stamps[0:55] Meet Joel Horwitz, CMO of Promo.com[1:35] Why are we talking about Michael Crichton?[5:41] What does Joel's work at Promo.com entail?[8:27] Who is Michael Crichton?[13:22] What was Michael Crichton's creative process?[17:35] What makes Michael Crichton remarkable?[32:56] What B2B marketing lessons can we take from Michael Crichton?[50:13] What have Joel's favorite campaigns been over the years?[53:10] What's next for Promo.com?LinksLearn more about Michael CrichtonConnect with Joel on LinkedInLearn more about Promo.comAbout Remarkable!Remarkable! is created by the team at Caspian Studios, the premier B2B Podcast-as-a-Service company. Caspian creates both non-fiction and fiction series for B2B companies. If you want a fiction series check out our new offering - The Business Thriller - Hollywood style storytelling for B2B. Learn more at CaspianStudios.com. In today's episode, you heard from Ian Faison (CEO of Caspian Studios) and Meredith Gooderham (Senior Producer). Remarkable was produced this week by Jess Avellino, mixed by Scott Goodrich, and our theme song is “Solomon” by FALAK. Create something remarkable. Rise above the noise.
CISA says Super Tuesday ran smoothly. The White House sanctions spyware vendors. The DoD launches its Cyber Operational Readiness Assessment program. NIST unveils an updated NICE Framework. Apple patches a pair of zero-days. The GhostSec and Stormous ransomware gangs join forces. Cado Security tracks a new Golang-based malware campaign. Google updates its search algorithms to fight spammy content. Canada's financial intelligence agency suffers a cyber incident. On our Industry Voices segment, our guest Amitai Cohen, Attack Vector Intel Lead at Wiz joins us to discuss cloud threats. Moonlighting on the dark side. Remember to leave us a 5-star rating and review in your favorite podcast app. Miss an episode? Sign-up for our daily intelligence roundup, Daily Briefing, and you'll never miss a beat. And be sure to follow CyberWire Daily on LinkedIn. CyberWire Guest On our Industry Voices segment, our guest Amitai Cohen, Attack Vector Intel Lead at Wiz and host of their Crying Out Cloud podcast, joins us to discuss cloud threats. Learn more in Wiz's State of the AI Cloud report. Selected Reading No security issues as Super Tuesday draws to a close, CISA official says (The Record) Biden administration sanctions makers of commercial spyware used to surveil US (CNN Business) US DoD launches CORA program to revolutionize cybersecurity strategy (Industrial Cyber) Unveiling NICE Framework Components v1.0.0: Explore the Latest Updates Today! (NIST) Update your iPhones and iPads now: Apple patches security vulnerabilities in iOS and iPadOS (Malwarebytes) Watch out, GhostSec and Stourmous groups jointly conducting ransomware attacks (Security Affairs) Hackers target Docker, Hadoop, Redis, Confluence with new Golang malware (Bleeping Computer) Google is starting to squash more spam and AI in search results (The Verge) Cyberattack forces Canada's financial intelligence agency to take systems offline (The Record) Cyber Pros Turn to Cybercrime as Salaries Stagnate (Infosecurity Magazine) Share your feedback. We want to ensure that you are getting the most out of the podcast. Please take a few minutes to share your thoughts with us by completing our brief listener survey as we continually work to improve the show. Want to hear your company in the show? You too can reach the most influential leaders and operators in the industry. Here's our media kit. Contact us at cyberwire@n2k.com to request more info. The CyberWire is a production of N2K Networks, your source for strategic workforce intelligence. © 2023 N2K Networks, Inc.

This week in the Security Weekly News: Avast fines, HackerGPT innovations, DDoS threats, encryption updates, Josh Marpet, and more! Visit https://www.securityweekly.com/swn for all the latest episodes! Show Notes: https://securityweekly.com/swn-364

This week in the Security Weekly News: Avast fines, HackerGPT innovations, DDoS threats, encryption updates, Josh Marpet, and more! Show Notes: https://securityweekly.com/swn-364

This week in the Security Weekly News: Avast fines, HackerGPT innovations, DDoS threats, encryption updates, Josh Marpet, and more! Visit https://www.securityweekly.com/swn for all the latest episodes! Show Notes: https://securityweekly.com/swn-364

We're writing this one day after the monster release of OpenAI's Sora and Gemini 1.5. We covered this on ‘s ThursdAI space, so head over there for our takes.IRL: We're ONE WEEK away from Latent Space: Final Frontiers, the second edition and anniversary of our first ever Latent Space event! Also: join us on June 25-27 for the biggest AI Engineer conference of the year!Online: All three Discord clubs are thriving. Join us every Wednesday/Friday!Almost 12 years ago, while working at Spotify, Erik Bernhardsson built one of the first open source vector databases, Annoy, based on ANN search. He also built Luigi, one of the predecessors to Airflow, which helps data teams orchestrate and execute data-intensive and long-running jobs. Surprisingly, he didn't start yet another vector database company, but instead in 2021 founded Modal, the “high-performance cloud for developers”. In 2022 they opened doors to developers after their seed round, and in 2023 announced their GA with a $16m Series A.More importantly, they have won fans among both household names like Ramp, Scale AI, Substack, and Cohere, and newer startups like (upcoming guest!) Suno.ai and individual hackers (Modal was the top tool of choice in the Vercel AI Accelerator):We've covered the nuances of GPU workloads, and how we need new developer tooling and runtimes for them (see our episodes with Chris Lattner of Modular and George Hotz of tiny to start). In this episode, we run through the major limitations of the actual infrastructure behind the clouds that run these models, and how Erik envisions the “postmodern data stack”. In his 2021 blog post “Software infrastructure 2.0: a wishlist”, Erik had “Truly serverless” as one of his points:* The word cluster is an anachronism to an end-user in the cloud! I'm already running things in the cloud where there's elastic resources available at any time. Why do I have to think about the underlying pool of resources? Just maintain it for me.* I don't ever want to provision anything in advance of load.* I don't want to pay for idle resources. Just let me pay for whatever resources I'm actually using.* Serverless doesn't mean it's a burstable VM that saves its instance state to disk during periods of idle.Swyx called this Self Provisioning Runtimes back in the day. Modal doesn't put you in YAML hell, preferring to colocate infra provisioning right next to the code that utilizes it, so you can just add GPU (and disk, and retries…):After 3 years, we finally have a big market push for this: running inference on generative models is going to be the killer app for serverless, for a few reasons:* AI models are stateless: even in conversational interfaces, each message generation is a fully-contained request to the LLM. There's no knowledge that is stored in the model itself between messages, which means that tear down / spin up of resources doesn't create any headaches with maintaining state.* Token-based pricing is better aligned with serverless infrastructure than fixed monthly costs of traditional software.* GPU scarcity makes it really expensive to have reserved instances that are available to you 24/7. It's much more convenient to build with a serverless-like infrastructure.In the episode we covered a lot more topics like maximizing GPU utilization, why Oracle Cloud rocks, and how Erik has never owned a TV in his life. Enjoy!Show Notes* Modal* ErikBot* Erik's Blog* Software Infra 2.0 Wishlist* Luigi* Annoy* Hetzner* CoreWeave* Cloudflare FaaS* Poolside AI* Modular Inference EngineChapters* [00:00:00] Introductions* [00:02:00] Erik's OSS work at Spotify: Annoy and Luigi* [00:06:22] Starting Modal* [00:07:54] Vision for a "postmodern data stack"* [00:10:43] Solving container cold start problems* [00:12:57] Designing Modal's Python SDK* [00:15:18] Self-Revisioning Runtime* [00:19:14] Truly Serverless Infrastructure* [00:20:52] Beyond model inference* [00:22:09] Tricks to maximize GPU utilization* [00:26:27] Differences in AI and data science workloads* [00:28:08] Modal vs Replicate vs Modular and lessons from Heroku's "graduation problem"* [00:34:12] Creating Erik's clone "ErikBot"* [00:37:43] Enabling massive parallelism across thousands of GPUs* [00:39:45] The Modal Sandbox for agents* [00:43:51] Thoughts on the AI Inference War* [00:49:18] Erik's best tweets* [00:51:57] Why buying hardware is a waste of money* [00:54:18] Erik's competitive programming backgrounds* [00:59:02] Why does Sweden have the best Counter Strike players?* [00:59:53] Never owning a car or TV* [01:00:21] Advice for infrastructure startupsTranscriptAlessio [00:00:00]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO-in-Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI.Swyx [00:00:14]: Hey, and today we have in the studio Erik Bernhardsson from Modal. Welcome.Erik [00:00:19]: Hi. It's awesome being here.Swyx [00:00:20]: Yeah. Awesome seeing you in person. I've seen you online for a number of years as you were building on Modal and I think you're just making a San Francisco trip just to see people here, right? I've been to like two Modal events in San Francisco here.Erik [00:00:34]: Yeah, that's right. We're based in New York, so I figured sometimes I have to come out to capital of AI and make a presence.Swyx [00:00:40]: What do you think is the pros and cons of building in New York?Erik [00:00:45]: I mean, I never built anything elsewhere. I lived in New York the last 12 years. I love the city. Obviously, there's a lot more stuff going on here and there's a lot more customers and that's why I'm out here. I do feel like for me, where I am in life, I'm a very boring person. I kind of work hard and then I go home and hang out with my kids. I don't have time to go to events and meetups and stuff anyway. In that sense, New York is kind of nice. I walk to work every morning. It's like five minutes away from my apartment. It's very time efficient in that sense. Yeah.Swyx [00:01:10]: Yeah. It's also a good life. So we'll do a brief bio and then we'll talk about anything else that people should know about you. Actually, I was surprised to find out you're from Sweden. You went to college in KTH and your master's was in implementing a scalable music recommender system. Yeah.Erik [00:01:27]: I had no idea. Yeah. So I actually studied physics, but I grew up coding and I did a lot of programming competition and then as I was thinking about graduating, I got in touch with an obscure music streaming startup called Spotify, which was then like 30 people. And for some reason, I convinced them, why don't I just come and write a master's thesis with you and I'll do some cool collaborative filtering, despite not knowing anything about collaborative filtering really. But no one knew anything back then. So I spent six months at Spotify basically building a prototype of a music recommendation system and then turned that into a master's thesis. And then later when I graduated, I joined Spotify full time.Swyx [00:02:00]: So that was the start of your data career. You also wrote a couple of popular open source tooling while you were there. Is that correct?Erik [00:02:09]: No, that's right. I mean, I was at Spotify for seven years, so this is a long stint. And Spotify was a wild place early on and I mean, data space is also a wild place. I mean, it was like Hadoop cluster in the like foosball room on the floor. It was a lot of crude, like very basic infrastructure and I didn't know anything about it. And like I was hired to kind of figure out data stuff. And I started hacking on a recommendation system and then, you know, got sidetracked in a bunch of other stuff. I fixed a bunch of reporting things and set up A-B testing and started doing like business analytics and later got back to music recommendation system. And a lot of the infrastructure didn't really exist. Like there was like Hadoop back then, which is kind of bad and I don't miss it. But I spent a lot of time with that. As a part of that, I ended up building a workflow engine called Luigi, which is like briefly like somewhat like widely ended up being used by a bunch of companies. Sort of like, you know, kind of like Airflow, but like before Airflow. I think it did some things better, some things worse. I also built a vector database called Annoy, which is like for a while, it was actually quite widely used. In 2012, so it was like way before like all this like vector database stuff ended up happening. And funny enough, I was actually obsessed with like vectors back then. Like I was like, this is going to be huge. Like just give it like a few years. I didn't know it was going to take like nine years and then there's going to suddenly be like 20 startups doing vector databases in one year. So it did happen. In that sense, I was right. I'm glad I didn't start a startup in the vector database space. I would have started way too early. But yeah, that was, yeah, it was a fun seven years as part of it. It was a great culture, a great company.Swyx [00:03:32]: Yeah. Just to take a quick tangent on this vector database thing, because we probably won't revisit it but like, has anything architecturally changed in the last nine years?Erik [00:03:41]: I'm actually not following it like super closely. I think, you know, some of the best algorithms are still the same as like hierarchical navigable small world.Swyx [00:03:51]: Yeah. HNSW.Erik [00:03:52]: Exactly. I think now there's like product quantization, there's like some other stuff that I haven't really followed super closely. I mean, obviously, like back then it was like, you know, it's always like very simple. It's like a C++ library with Python bindings and you could mmap big files and into memory and like they had some lookups. I used like this kind of recursive, like hyperspace splitting strategy, which is not that good, but it sort of was good enough at that time. But I think a lot of like HNSW is still like what people generally use. Now of course, like databases are much better in the sense like to support like inserts and updates and stuff like that. I know I never supported that. Yeah, it's sort of exciting to finally see like vector databases becoming a thing.Swyx [00:04:30]: Yeah. Yeah. And then maybe one takeaway on most interesting lesson from Daniel Ek?Erik [00:04:36]: I mean, I think Daniel Ek, you know, he started Spotify very young. Like he was like 25, something like that. And that was like a good lesson. But like he, in a way, like I think he was a very good leader. Like there was never anything like, no scandals or like no, he wasn't very eccentric at all. It was just kind of like very like level headed, like just like ran the company very well, like never made any like obvious mistakes or I think it was like a few bets that maybe like in hindsight were like a little, you know, like took us, you know, too far in one direction or another. But overall, I mean, I think he was a great CEO, like definitely, you know, up there, like generational CEO, at least for like Swedish startups.Swyx [00:05:09]: Yeah, yeah, for sure. Okay, we should probably move to make our way towards Modal. So then you spent six years as CTO of Better. You were an early engineer and then you scaled up to like 300 engineers.Erik [00:05:21]: I joined as a CTO when there was like no tech team. And yeah, that was a wild chapter in my life. Like the company did very well for a while. And then like during the pandemic, yeah, it was kind of a weird story, but yeah, it kind of collapsed.Swyx [00:05:32]: Yeah, laid off people poorly.Erik [00:05:34]: Yeah, yeah. It was like a bunch of stories. Yeah. I mean, the company like grew from like 10 people when I joined at 10,000, now it's back to a thousand. But yeah, they actually went public a few months ago, kind of crazy. They're still around, like, you know, they're still, you know, doing stuff. So yeah, very kind of interesting six years of my life for non-technical reasons, like I managed like three, four hundred, but yeah, like learning a lot of that, like recruiting. I spent all my time recruiting and stuff like that. And so managing at scale, it's like nice, like now in a way, like when I'm building my own startup. It's actually something I like, don't feel nervous about at all. Like I've managed a scale, like I feel like I can do it again. It's like very different things that I'm nervous about as a startup founder. But yeah, I started Modal three years ago after sort of, after leaving Better, I took a little bit of time off during the pandemic and, but yeah, pretty quickly I was like, I got to build something. I just want to, you know. Yeah. And then yeah, Modal took form in my head, took shape.Swyx [00:06:22]: And as far as I understand, and maybe we can sort of trade off questions. So the quick history is started Modal in 2021, got your seed with Sarah from Amplify in 2022. You just announced your Series A with Redpoint. That's right. And that brings us up to mostly today. Yeah. Most people, I think, were expecting you to build for the data space.Erik: But it is the data space.Swyx:: When I think of data space, I come from like, you know, Snowflake, BigQuery, you know, Fivetran, Nearby, that kind of stuff. And what Modal became is more general purpose than that. Yeah.Erik [00:06:53]: Yeah. I don't know. It was like fun. I actually ran into like Edo Liberty, the CEO of Pinecone, like a few weeks ago. And he was like, I was so afraid you were building a vector database. No, I started Modal because, you know, like in a way, like I work with data, like throughout my most of my career, like every different part of the stack, right? Like I thought everything like business analytics to like deep learning, you know, like building, you know, training neural networks, the scale, like everything in between. And so one of the thoughts, like, and one of the observations I had when I started Modal or like why I started was like, I just wanted to make, build better tools for data teams. And like very, like sort of abstract thing, but like, I find that the data stack is, you know, full of like point solutions that don't integrate well. And still, when you look at like data teams today, you know, like every startup ends up building their own internal Kubernetes wrapper or whatever. And you know, all the different data engineers and machine learning engineers end up kind of struggling with the same things. So I started thinking about like, how do I build a new data stack, which is kind of a megalomaniac project, like, because you kind of want to like throw out everything and start over.Swyx [00:07:54]: It's almost a modern data stack.Erik [00:07:55]: Yeah, like a postmodern data stack. And so I started thinking about that. And a lot of it came from like, like more focused on like the human side of like, how do I make data teams more productive? And like, what is the technology tools that they need? And like, you know, drew out a lot of charts of like, how the data stack looks, you know, what are different components. And it shows actually very interesting, like workflow scheduling, because it kind of sits in like a nice sort of, you know, it's like a hub in the graph of like data products. But it was kind of hard to like, kind of do that in a vacuum, and also to monetize it to some extent. I got very interested in like the layers below at some point. And like, at the end of the day, like most people have code to have to run somewhere. So I think about like, okay, well, how do you make that nice? Like how do you make that? And in particular, like the thing I always like thought about, like developer productivity is like, I think the best way to measure developer productivity is like in terms of the feedback loops, like how quickly when you iterate, like when you write code, like how quickly can you get feedback. And at the innermost loop, it's like writing code and then running it. And like, as soon as you start working with the cloud, like it's like takes minutes suddenly, because you have to build a Docker container and push it to the cloud and like run it, you know. So that was like the initial focus for me was like, I just want to solve that problem. Like I want to, you know, build something less, you run things in the cloud and like retain the sort of, you know, the joy of productivity as when you're running things locally. And in particular, I was quite focused on data teams, because I think they had a couple unique needs that wasn't well served by the infrastructure at that time, or like still is in like, in particular, like Kubernetes, I feel like it's like kind of worked okay for back end teams, but not so well for data teams. And very quickly, I got sucked into like a very deep like rabbit hole of like...Swyx [00:09:24]: Not well for data teams because of burstiness. Yeah, for sure.Erik [00:09:26]: So like burstiness is like one thing, right? Like, you know, like you often have this like fan out, you want to like apply some function over very large data sets. Another thing tends to be like hardware requirements, like you need like GPUs and like, I've seen this in many companies, like you go, you know, data scientists go to a platform team and they're like, can we add GPUs to the Kubernetes? And they're like, no, like, that's, you know, complex, and we're not gonna, so like just getting GPU access. And then like, I mean, I also like data code, like frankly, or like machine learning code like tends to be like, super annoying in terms of like environments, like you end up having like a lot of like custom, like containers and like environment conflicts. And like, it's very hard to set up like a unified container that like can serve like a data scientist, because like, there's always like packages that break. And so I think there's a lot of different reasons why the technology wasn't well suited for back end. And I think the attitude at that time is often like, you know, like you had friction between the data team and the platform team, like, well, it works for the back end stuff, you know, why don't you just like, you know, make it work. But like, I actually felt like data teams, you know, or at this point now, like there's so much, so many people working with data, and like they, to some extent, like deserve their own tools and their own tool chains, and like optimizing for that is not something people have done. So that's, that's sort of like very abstract philosophical reason why I started Model. And then, and then I got sucked into this like rabbit hole of like container cold start and, you know, like whatever, Linux, page cache, you know, file system optimizations.Swyx [00:10:43]: Yeah, tell people, I think the first time I met you, I think you told me some numbers, but I don't remember, like, what are the main achievements that you were unhappy with the status quo? And then you built your own container stack?Erik [00:10:52]: Yeah, I mean, like, in particular, it was like, in order to have that loop, right? You want to be able to start, like take code on your laptop, whatever, and like run in the cloud very quickly, and like running in custom containers, and maybe like spin up like 100 containers, 1000, you know, things like that. And so container cold start was the initial like, from like a developer productivity point of view, it was like, really, what I was focusing on is, I want to take code, I want to stick it in container, I want to execute in the cloud, and like, you know, make it feel like fast. And when you look at like, how Docker works, for instance, like Docker, you have this like, fairly convoluted, like very resource inefficient way, they, you know, you build a container, you upload the whole container, and then you download it, and you run it. And Kubernetes is also like, not very fast at like starting containers. So like, I started kind of like, you know, going a layer deeper, like Docker is actually like, you know, there's like a couple of different primitives, but like a lower level primitive is run C, which is like a container runner. And I was like, what if I just take the container runner, like run C, and I point it to like my own root file system, and then I built like my own virtual file system that exposes files over a network instead. And that was like the sort of very crude version of model, it's like now I can actually start containers very quickly, because it turns out like when you start a Docker container, like, first of all, like most Docker images are like several gigabytes, and like 99% of that is never going to be consumed, like there's a bunch of like, you know, like timezone information for like Uzbekistan, like no one's going to read it. And then there's a very high overlap between the files are going to be read, there's going to be like lib torch or whatever, like it's going to be read. So you can also cache it very well. So that was like the first sort of stuff we started working on was like, let's build this like container file system. And you know, coupled with like, you know, just using run C directly. And that actually enabled us to like, get to this point of like, you write code, and then you can launch it in the cloud within like a second or two, like something like that. And you know, there's been many optimizations since then, but that was sort of starting point.Alessio [00:12:33]: Can we talk about the developer experience as well, I think one of the magic things about Modal is at the very basic layers, like a Python function decorator, it's just like stub and whatnot. But then you also have a way to define a full container, what were kind of the design decisions that went into it? Where did you start? How easy did you want it to be? And then maybe how much complexity did you then add on to make sure that every use case fit?Erik [00:12:57]: I mean, Modal, I almost feel like it's like almost like two products kind of glued together. Like there's like the low level like container runtime, like file system, all that stuff like in Rust. And then there's like the Python SDK, right? Like how do you express applications? And I think, I mean, Swix, like I think your blog was like the self-provisioning runtime was like, to me, always like to sort of, for me, like an eye-opening thing. It's like, so I didn't think about like...Swyx [00:13:15]: You wrote your post four months before me. Yeah? The software 2.0, Infra 2.0. Yeah.Erik [00:13:19]: Well, I don't know, like convergence of minds. I guess we were like both thinking. Maybe you put, I think, better words than like, you know, maybe something I was like thinking about for a long time. Yeah.Swyx [00:13:29]: And I can tell you how I was thinking about it on my end, but I want to hear you say it.Erik [00:13:32]: Yeah, yeah, I would love to. So to me, like what I always wanted to build was like, I don't know, like, I don't know if you use like Pulumi. Like Pulumi is like nice, like in the sense, like it's like Pulumi is like you describe infrastructure in code, right? And to me, that was like so nice. Like finally I can like, you know, put a for loop that creates S3 buckets or whatever. And I think like Modal sort of goes one step further in the sense that like, what if you also put the app code inside the infrastructure code and like glue it all together and then like you only have one single place that defines everything and it's all programmable. You don't have any config files. Like Modal has like zero config. There's no config. It's all code. And so that was like the goal that I wanted, like part of that. And then the other part was like, I often find that so much of like my time was spent on like the plumbing between containers. And so my thing was like, well, if I just build this like Python SDK and make it possible to like bridge like different containers, just like a function call, like, and I can say, oh, this function runs in this container and this other function runs in this container and I can just call it just like a normal function, then, you know, I can build these applications that may span a lot of different environments. Maybe they fan out, start other containers, but it's all just like inside Python. You just like have this beautiful kind of nice like DSL almost for like, you know, how to control infrastructure in the cloud. So that was sort of like how we ended up with the Python SDK as it is, which is still evolving all the time, by the way. We keep changing syntax quite a lot because I think it's still somewhat exploratory, but we're starting to converge on something that feels like reasonably good now.Swyx [00:14:54]: Yeah. And along the way you, with this expressiveness, you enabled the ability to, for example, attach a GPU to a function. Totally.Erik [00:15:02]: Yeah. It's like you just like say, you know, on the function decorator, you're like GPU equals, you know, A100 and then or like GPU equals, you know, A10 or T4 or something like that. And then you get that GPU and like, you know, you just run the code and it runs like you don't have to, you know, go through hoops to, you know, start an EC2 instance or whatever.Swyx [00:15:18]: Yeah. So it's all code. Yeah. So one of the reasons I wrote Self-Revisioning Runtimes was I was working at AWS and we had AWS CDK, which is kind of like, you know, the Amazon basics blew me. Yeah, totally. And then, and then like it creates, it compiles the cloud formation. Yeah. And then on the other side, you have to like get all the config stuff and then put it into your application code and make sure that they line up. So then you're writing code to define your infrastructure, then you're writing code to define your application. And I was just like, this is like obvious that it's going to converge, right? Yeah, totally.Erik [00:15:48]: But isn't there like, it might be wrong, but like, was it like SAM or Chalice or one of those? Like, isn't that like an AWS thing that where actually they kind of did that? I feel like there's like one.Swyx [00:15:57]: SAM. Yeah. Still very clunky. It's not, not as elegant as modal.Erik [00:16:03]: I love AWS for like the stuff it's built, you know, like historically in order for me to like, you know, what it enables me to build, but like AWS is always like struggle with developer experience.Swyx [00:16:11]: I mean, they have to not break things.Erik [00:16:15]: Yeah. Yeah. And totally. And they have to build products for a very wide range of use cases. And I think that's hard.Swyx [00:16:21]: Yeah. Yeah. So it's, it's easier to design for. Yeah. So anyway, I was, I was pretty convinced that this, this would happen. I wrote, wrote that thing. And then, you know, I imagine my surprise that you guys had it on your landing page at some point. I think, I think Akshad was just like, just throw that in there.Erik [00:16:34]: Did you trademark it?Swyx [00:16:35]: No, I didn't. But I definitely got sent a few pitch decks with my post on there and it was like really interesting. This is my first time like kind of putting a name to a phenomenon. And I think this is a useful skill for people to just communicate what they're trying to do.Erik [00:16:48]: Yeah. No, I think it's a beautiful concept.Swyx [00:16:50]: Yeah. Yeah. Yeah. But I mean, obviously you implemented it. What became more clear in your explanation today is that actually you're not that tied to Python.Erik [00:16:57]: No. I mean, I, I think that all the like lower level stuff is, you know, just running containers and like scheduling things and, you know, serving container data and stuff. So like one of the benefits of data teams is obviously like they're all like using Python, right? And so that made it a lot easier. I think, you know, if we had focused on other workloads, like, you know, for various reasons, we've like been kind of like half thinking about like CI or like things like that. But like, in a way that's like harder because like you also, then you have to be like, you know, multiple SDKs, whereas, you know, focusing on data teams, you can only, you know, Python like covers like 95% of all teams. That made it a lot easier. But like, I mean, like definitely like in the future, we're going to have others support, like supporting other languages. JavaScript for sure is the obvious next language. But you know, who knows, like, you know, Rust, Go, R, whatever, PHP, Haskell, I don't know.Swyx [00:17:42]: You know, I think for me, I actually am a person who like kind of liked the idea of programming language advancements being improvements in developer experience. But all I saw out of the academic sort of PLT type people is just type level improvements. And I always think like, for me, like one of the core reasons for self-provisioning runtimes and then why I like Modal is like, this is actually a productivity increase, right? Like, it's a language level thing, you know, you managed to stick it on top of an existing language, but it is your own language, a DSL on top of Python. And so language level increase on the order of like automatic memory management. You know, you could sort of make that analogy that like, maybe you lose some level of control, but most of the time you're okay with whatever Modal gives you. And like, that's fine. Yeah.Erik [00:18:26]: Yeah. Yeah. I mean, that's how I look at about it too. Like, you know, you look at developer productivity over the last number of decades, like, you know, it's come in like small increments of like, you know, dynamic typing or like is like one thing because not suddenly like for a lot of use cases, you don't need to care about type systems or better compiler technology or like, you know, the cloud or like, you know, relational databases. And, you know, I think, you know, you look at like that, you know, history, it's a steadily, you know, it's like, you know, you look at the developers have been getting like probably 10X more productive every decade for the last four decades or something that was kind of crazy. Like on an exponential scale, we're talking about 10X or is there a 10,000X like, you know, improvement in developer productivity. What we can build today, you know, is arguably like, you know, a fraction of the cost of what it took to build it in the eighties. Maybe it wasn't even possible in the eighties. So that to me, like, that's like so fascinating. I think it's going to keep going for the next few decades. Yeah.Alessio [00:19:14]: Yeah. Another big thing in the infra 2.0 wishlist was truly serverless infrastructure. The other on your landing page, you called them native cloud functions, something like that. I think the issue I've seen with serverless has always been people really wanted it to be stateful, even though stateless was much easier to do. And I think now with AI, most model inference is like stateless, you know, outside of the context. So that's kind of made it a lot easier to just put a model, like an AI model on model to run. How do you think about how that changes how people think about infrastructure too? Yeah.Erik [00:19:48]: I mean, I think model is definitely going in the direction of like doing more stateful things and working with data and like high IO use cases. I do think one like massive serendipitous thing that happened like halfway, you know, a year and a half into like the, you know, building model was like Gen AI started exploding and the IO pattern of Gen AI is like fits the serverless model like so well, because it's like, you know, you send this tiny piece of information, like a prompt, right, or something like that. And then like you have this GPU that does like trillions of flops, and then it sends back like a tiny piece of information, right. And that turns out to be something like, you know, if you can get serverless working with GPU, that just like works really well, right. So I think from that point of view, like serverless always to me felt like a little bit of like a solution looking for a problem. I don't actually like don't think like backend is like the problem that needs to serve it or like not as much. But I look at data and in particular, like things like Gen AI, like model inference, like it's like clearly a good fit. So I think that is, you know, to a large extent explains like why we saw, you know, the initial sort of like killer app for model being model inference, which actually wasn't like necessarily what we're focused on. But that's where we've seen like by far the most usage. Yeah.Swyx [00:20:52]: And this was before you started offering like fine tuning of language models, it was mostly stable diffusion. Yeah.Erik [00:20:59]: Yeah. I mean, like model, like I always built it to be a very general purpose compute platform, like something where you can run everything. And I used to call model like a better Kubernetes for data team for a long time. What we realized was like, yeah, that's like, you know, a year and a half in, like we barely had any users or any revenue. And like we were like, well, maybe we should look at like some use case, trying to think of use case. And that was around the same time stable diffusion came out. And the beauty of model is like you can run almost anything on model, right? Like model inference turned out to be like the place where we found initially, well, like clearly this has like 10x like better agronomics than anything else. But we're also like, you know, going back to my original vision, like we're thinking a lot about, you know, now, okay, now we do inference really well. Like what about training? What about fine tuning? What about, you know, end-to-end lifecycle deployment? What about data pre-processing? What about, you know, I don't know, real-time streaming? What about, you know, large data munging, like there's just data observability. I think there's so many things, like kind of going back to what I said about like redefining the data stack, like starting with the foundation of compute. Like one of the exciting things about model is like we've sort of, you know, we've been working on that for three years and it's maturing, but like this is so many things you can do like with just like a better compute primitive and also go up to stack and like do all this other stuff on top of it.Alessio [00:22:09]: How do you think about or rather like I would love to learn more about the underlying infrastructure and like how you make that happen because with fine tuning and training, it's a static memory. Like you exactly know what you're going to load in memory one and it's kind of like a set amount of compute versus inference, just like data is like very bursty. How do you make batches work with a serverless developer experience? You know, like what are like some fun technical challenge you solve to make sure you get max utilization on these GPUs? What we hear from people is like, we have GPUs, but we can really only get like, you know, 30, 40, 50% maybe utilization. What's some of the fun stuff you're working on to get a higher number there?Erik [00:22:48]: Yeah, I think on the inference side, like that's where we like, you know, like from a cost perspective, like utilization perspective, we've seen, you know, like very good numbers and in particular, like it's our ability to start containers and stop containers very quickly. And that means that we can auto scale extremely fast and scale down very quickly, which means like we can always adjust the sort of capacity, the number of GPUs running to the exact traffic volume. And so in many cases, like that actually leads to a sort of interesting thing where like we obviously run our things on like the public cloud, like AWS GCP, we run on Oracle, but in many cases, like users who do inference on those platforms or those clouds, even though we charge a slightly higher price per GPU hour, a lot of users like moving their large scale inference use cases to model, they end up saving a lot of money because we only charge for like with the time the GPU is actually running. And that's a hard problem, right? Like, you know, if you have to constantly adjust the number of machines, if you have to start containers, stop containers, like that's a very hard problem. Starting containers quickly is a very difficult thing. I mentioned we had to build our own file system for this. We also, you know, built our own container scheduler for that. We've implemented recently CPU memory checkpointing so we can take running containers and snapshot the entire CPU, like including registers and everything, and restore it from that point, which means we can restore it from an initialized state. We're looking at GPU checkpointing next, it's like a very interesting thing. So I think with inference stuff, that's where serverless really shines because you can drive, you know, you can push the frontier of latency versus utilization quite substantially, you know, which either ends up being a latency advantage or a cost advantage or both, right? On training, it's probably arguably like less of an advantage doing serverless, frankly, because you know, you can just like spin up a bunch of machines and try to satisfy, like, you know, train as much as you can on each machine. For that area, like we've seen, like, you know, arguably like less usage, like for modal, but there are always like some interesting use case. Like we do have a couple of customers, like RAM, for instance, like they do fine tuning with modal and they basically like one of the patterns they have is like very bursty type fine tuning where they fine tune 100 models in parallel. And that's like a separate thing that modal does really well, right? Like you can, we can start up 100 containers very quickly, run a fine tuning training job on each one of them for that only runs for, I don't know, 10, 20 minutes. And then, you know, you can do hyper parameter tuning in that sense, like just pick the best model and things like that. So there are like interesting training. I think when you get to like training, like very large foundational models, that's a use case we don't support super well, because that's very high IO, you know, you need to have like infinite band and all these things. And those are things we haven't supported yet and might take a while to get to that. So that's like probably like an area where like we're relatively weak in. Yeah.Alessio [00:25:12]: Have you cared at all about lower level model optimization? There's other cloud providers that do custom kernels to get better performance or are you just given that you're not just an AI compute company? Yeah.Erik [00:25:24]: I mean, I think like we want to support like a generic, like general workloads in a sense that like we want users to give us a container essentially or a code or code. And then we want to run that. So I think, you know, we benefit from those things in the sense that like we can tell our users, you know, to use those things. But I don't know if we want to like poke into users containers and like do those things automatically. That's sort of, I think a little bit tricky from the outside to do, because we want to be able to take like arbitrary code and execute it. But certainly like, you know, we can tell our users to like use those things. Yeah.Swyx [00:25:53]: I may have betrayed my own biases because I don't really think about modal as for data teams anymore. I think you started, I think you're much more for AI engineers. My favorite anecdotes, which I think, you know, but I don't know if you directly experienced it. I went to the Vercel AI Accelerator, which you supported. And in the Vercel AI Accelerator, a bunch of startups gave like free credits and like signups and talks and all that stuff. The only ones that stuck are the ones that actually appealed to engineers. And the top usage, the top tool used by far was modal.Erik [00:26:24]: That's awesome.Swyx [00:26:25]: For people building with AI apps. Yeah.Erik [00:26:27]: I mean, it might be also like a terminology question, like the AI versus data, right? Like I've, you know, maybe I'm just like old and jaded, but like, I've seen so many like different titles, like for a while it was like, you know, I was a data scientist and a machine learning engineer and then, you know, there was like analytics engineers and there was like an AI engineer, you know? So like, to me, it's like, I just like in my head, that's to me just like, just data, like, or like engineer, you know, like I don't really, so that's why I've been like, you know, just calling it data teams. But like, of course, like, you know, AI is like, you know, like such a massive fraction of our like workloads.Swyx [00:26:59]: It's a different Venn diagram of things you do, right? So the stuff that you're talking about where you need like infinite bands for like highly parallel training, that's not, that's more of the ML engineer, that's more of the research scientist and less of the AI engineer, which is more sort of trying to put, work at the application.Erik [00:27:16]: Yeah. I mean, to be fair to it, like we have a lot of users that are like doing stuff that I don't think fits neatly into like AI. Like we have a lot of people using like modal for web scraping, like it's kind of nice. You can just like, you know, fire up like a hundred or a thousand containers running Chromium and just like render a bunch of webpages and it takes, you know, whatever. Or like, you know, protein folding is that, I mean, maybe that's, I don't know, like, but like, you know, we have a bunch of users doing that or, or like, you know, in terms of, in the realm of biotech, like sequence alignment, like people using, or like a couple of people using like modal to run like large, like mixed integer programming problems, like, you know, using Gurobi or like things like that. So video processing is another thing that keeps coming up, like, you know, let's say you have like petabytes of video and you want to just like transcode it, like, or you can fire up a lot of containers and just run FFmpeg or like, so there are those things too. Like, I mean, like that being said, like AI is by far our biggest use case, but you know, like, again, like modal is kind of general purpose in that sense.Swyx [00:28:08]: Yeah. Well, maybe I'll stick to the stable diffusion thing and then we'll move on to the other use cases for AI that you want to highlight. The other big player in my mind is replicate. Yeah. In this, in this era, they're much more, I guess, custom built for that purpose, whereas you're more general purpose. How do you position yourself with them? Are they just for like different audiences or are you just heads on competing?Erik [00:28:29]: I think there's like a tiny sliver of the Venn diagram where we're competitive. And then like 99% of the area we're not competitive. I mean, I think for people who, if you look at like front-end engineers, I think that's where like really they found good fit is like, you know, people who built some cool web app and they want some sort of AI capability and they just, you know, an off the shelf model is like perfect for them. That's like, I like use replicate. That's great. I think where we shine is like custom models or custom workflows, you know, running things at very large scale. We need to care about utilization, care about costs. You know, we have much lower prices because we spend a lot more time optimizing our infrastructure, you know, and that's where we're competitive, right? Like, you know, and you look at some of the use cases, like Suno is a big user, like they're running like large scale, like AI. Oh, we're talking with Mikey.Swyx [00:29:12]: Oh, that's great. Cool.Erik [00:29:14]: In a month. Yeah. So, I mean, they're, they're using model for like production infrastructure. Like they have their own like custom model, like custom code and custom weights, you know, for AI generated music, Suno.AI, you know, that, that, those are the types of use cases that we like, you know, things that are like very custom or like, it's like, you know, and those are the things like it's very hard to run and replicate, right? And that's fine. Like I think they, they focus on a very different part of the stack in that sense.Swyx [00:29:35]: And then the other company pattern that I pattern match you to is Modular. I don't know.Erik [00:29:40]: Because of the names?Swyx [00:29:41]: No, no. Wow. No, but yeah, yes, the name is very similar. I think there's something that might be insightful there from a linguistics point of view. Oh no, they have Mojo, the sort of Python SDK. And they have the Modular Inference Engine, which is their sort of their cloud stack, their sort of compute inference stack. I don't know if anyone's made that comparison to you before, but like I see you evolving a little bit in parallel there.Erik [00:30:01]: No, I mean, maybe. Yeah. Like it's not a company I'm like super like familiar, like, I mean, I know the basics, but like, I guess they're similar in the sense like they want to like do a lot of, you know, they have sort of big picture vision.Swyx [00:30:12]: Yes. They also want to build very general purpose. Yeah. So they're marketing themselves as like, if you want to do off the shelf stuff, go out, go somewhere else. If you want to do custom stuff, we're the best place to do it. Yeah. Yeah. There is some overlap there. There's not overlap in the sense that you are a closed source platform. People have to host their code on you. That's true. Whereas for them, they're very insistent on not running their own cloud service. They're a box software. Yeah. They're licensed software.Erik [00:30:37]: I'm sure their VCs at some point going to force them to reconsider. No, no.Swyx [00:30:40]: Chris is very, very insistent and very convincing. So anyway, I would just make that comparison, let people make the links if they want to. But it's an interesting way to see the cloud market develop from my point of view, because I came up in this field thinking cloud is one thing, and I think your vision is like something slightly different, and I see the different takes on it.Erik [00:31:00]: Yeah. And like one thing I've, you know, like I've written a bit about it in my blog too, it's like I think of us as like a second layer of cloud provider in the sense that like I think Snowflake is like kind of a good analogy. Like Snowflake, you know, is infrastructure as a service, right? But they actually run on the like major clouds, right? And I mean, like you can like analyze this very deeply, but like one of the things I always thought about is like, why does Snowflake arbitrarily like win over Redshift? And I think Snowflake, you know, to me, one, because like, I mean, in the end, like AWS makes all the money anyway, like and like Snowflake just had the ability to like focus on like developer experience or like, you know, user experience. And to me, like really proved that you can build a cloud provider, a layer up from, you know, the traditional like public clouds. And in that layer, that's also where I would put Modal, it's like, you know, we're building a cloud provider, like we're, you know, we're like a multi-tenant environment that runs the user code. But we're also building on top of the public cloud. So I think there's a lot of room in that space, I think is very sort of interesting direction.Alessio [00:31:55]: How do you think of that compared to the traditional past history, like, you know, you had AWS, then you had Heroku, then you had Render, Railway.Erik [00:32:04]: Yeah, I mean, I think those are all like great. I think the problem that they all faced was like the graduation problem, right? Like, you know, Heroku or like, I mean, like also like Heroku, there's like a counterfactual future of like, what would have happened if Salesforce didn't buy them, right? Like, that's a sort of separate thing. But like, I think what Heroku, I think always struggled with was like, eventually companies would get big enough that you couldn't really justify running in Heroku. So they would just go and like move it to, you know, whatever AWS or, you know, in particular. And you know, that's something that keeps me up at night too, like, what does that graduation risk like look like for modal? I always think like the only way to build a successful infrastructure company in the long run in the cloud today is you have to appeal to the entire spectrum, right? Or at least like the enterprise, like you have to capture the enterprise market. But the truly good companies capture the whole spectrum, right? Like I think of companies like, I don't like Datadog or Mongo or something that were like, they both captured like the hobbyists and acquire them, but also like, you know, have very large enterprise customers. I think that arguably was like where I, in my opinion, like Heroku struggle was like, how do you maintain the customers as they get more and more advanced? I don't know what the solution is, but I think there's, you know, that's something I would have thought deeply if I was at Heroku at that time.Alessio [00:33:14]: What's the AI graduation problem? Is it, I need to fine tune the model, I need better economics, any insights from customer discussions?Erik [00:33:22]: Yeah, I mean, better economics, certainly. But although like, I would say like, even for people who like, you know, needs like thousands of GPUs, just because we can drive utilization so much better, like we, there's actually like a cost advantage of staying on modal. But yeah, I mean, certainly like, you know, and like the fact that VCs like love, you know, throwing money at least used to, you know, add companies who need it to buy GPUs. I think that didn't help the problem. And in training, I think, you know, there's less software differentiation. So in training, I think there's certainly like better economics of like buying big clusters. But I mean, my hope it's going to change, right? Like I think, you know, we're still pretty early in the cycle of like building AI infrastructure. And I think a lot of these companies over in the long run, like, you know, they're, except it may be super big ones, like, you know, on Facebook and Google, they're always going to build their own ones. But like everyone else, like some extent, you know, I think they're better off like buying platforms. And, you know, someone's going to have to build those platforms.Swyx [00:34:12]: Yeah. Cool. Let's move on to language models and just specifically that workload just to flesh it out a little bit. You already said that RAMP is like fine tuning 100 models at once simultaneously on modal. Closer to home, my favorite example is ErikBot. Maybe you want to tell that story.Erik [00:34:30]: Yeah. I mean, it was a prototype thing we built for fun, but it's pretty cool. Like we basically built this thing that hooks up to Slack. It like downloads all the Slack history and, you know, fine-tunes a model based on a person. And then you can chat with that. And so you can like, you know, clone yourself and like talk to yourself on Slack. I mean, it's like nice like demo and it's just like, I think like it's like fully contained modal. Like there's a modal app that does everything, right? Like it downloads Slack, you know, integrates with the Slack API, like downloads the stuff, the data, like just runs the fine-tuning and then like creates like dynamically an inference endpoint. And it's all like self-contained and like, you know, a few hundred lines of code. So I think it's sort of a good kind of use case for, or like it kind of demonstrates a lot of the capabilities of modal.Alessio [00:35:08]: Yeah. On a more personal side, how close did you feel ErikBot was to you?Erik [00:35:13]: It definitely captured the like the language. Yeah. I mean, I don't know, like the content, I always feel this way about like AI and it's gotten better. Like when you look at like AI output of text, like, and it's like, when you glance at it, it's like, yeah, this seems really smart, you know, but then you actually like look a little bit deeper. It's like, what does this mean?Swyx [00:35:32]: What does this person say?Erik [00:35:33]: It's like kind of vacuous, right? And that's like kind of what I felt like, you know, talking to like my clone version, like it's like says like things like the grammar is correct. Like some of the sentences make a lot of sense, but like, what are you trying to say? Like there's no content here. I don't know. I mean, it's like, I got that feeling also with chat TBT in the like early versions right now it's like better, but.Alessio [00:35:51]: That's funny. So I built this thing called small podcaster to automate a lot of our back office work, so to speak. And it's great at transcript. It's great at doing chapters. And then I was like, okay, how about you come up with a short summary? And it's like, it sounds good, but it's like, it's not even the same ballpark as like, yeah, end up writing. Right. And it's hard to see how it's going to get there.Swyx [00:36:11]: Oh, I have ideas.Erik [00:36:13]: I'm certain it's going to get there, but like, I agree with you. Right. And like, I have the same thing. I don't know if you've read like AI generated books. Like they just like kind of seem funny, right? Like there's off, right? But like you glance at it and it's like, oh, it's kind of cool. Like looks correct, but then it's like very weird when you actually read them.Swyx [00:36:30]: Yeah. Well, so for what it's worth, I think anyone can join the modal slack. Is it open to the public? Yeah, totally.Erik [00:36:35]: If you go to modal.com, there's a button in the footer.Swyx [00:36:38]: Yeah. And then you can talk to Erik Bot. And then sometimes I really like picking Erik Bot and then you answer afterwards, but then you're like, yeah, mostly correct or whatever. Any other broader lessons, you know, just broadening out from like the single use case of fine tuning, like what are you seeing people do with fine tuning or just language models on modal in general? Yeah.Erik [00:36:59]: I mean, I think language models is interesting because so many people get started with APIs and that's just, you know, they're just dominating a space in particular opening AI, right? And that's not necessarily like a place where we aim to compete. I mean, maybe at some point, but like, it's just not like a core focus for us. And I think sort of separately, it's sort of a question of like, there's economics in that long term. But like, so we tend to focus on more like the areas like around it, right? Like fine tuning, like another use case we have is a bunch of people, Ramp included, is doing batch embeddings on modal. So let's say, you know, you have like a, actually we're like writing a blog post, like we take all of Wikipedia and like parallelize embeddings in 15 minutes and produce vectors for each article. So those types of use cases, I think modal suits really well for. I think also a lot of like custom inference, like yeah, I love that.Swyx [00:37:43]: Yeah. I think you should give people an idea of the order of magnitude of parallelism, because I think people don't understand how parallel. So like, I think your classic hello world with modal is like some kind of Fibonacci function, right? Yeah, we have a bunch of different ones. Some recursive function. Yeah.Erik [00:37:59]: Yeah. I mean, like, yeah, I mean, it's like pretty easy in modal, like fan out to like, you know, at least like 100 GPUs, like in a few seconds. And you know, if you give it like a couple of minutes, like we can, you know, you can fan out to like thousands of GPUs. Like we run it relatively large scale. And yeah, we've run, you know, many thousands of GPUs at certain points when we needed, you know, big backfills or some customers had very large compute needs.Swyx [00:38:21]: Yeah. Yeah. And I mean, that's super useful for a number of things. So one of my early interactions with modal as well was with a small developer, which is my sort of coding agent. The reason I chose modal was a number of things. One, I just wanted to try it out. I just had an excuse to try it. Akshay offered to onboard me personally. But the most interesting thing was that you could have that sort of local development experience as it was running on my laptop, but then it would seamlessly translate to a cloud service or like a cloud hosted environment. And then it could fan out with concurrency controls. So I could say like, because like, you know, the number of times I hit the GPT-3 API at the time was going to be subject to the rate limit. But I wanted to fan out without worrying about that kind of stuff. With modal, I can just kind of declare that in my config and that's it. Oh, like a concurrency limit?Erik [00:39:07]: Yeah. Yeah.Swyx [00:39:09]: Yeah. There's a lot of control. And that's why it's like, yeah, this is a pretty good use case for like writing this kind of LLM application code inside of this environment that just understands fan out and rate limiting natively. You don't actually have an exposed queue system, but you have it under the hood, you know, that kind of stuff. Totally.Erik [00:39:28]: It's a self-provisioning cloud.Swyx [00:39:30]: So the last part of modal I wanted to touch on, and obviously feel free, I know you're working on new features, was the sandbox that was introduced last year. And this is something that I think was inspired by Code Interpreter. You can tell me the longer history behind that.Erik [00:39:45]: Yeah. Like we originally built it for the use case, like there was a bunch of customers who looked into code generation applications and then they came to us and asked us, is there a safe way to execute code? And yeah, we spent a lot of time on like container security. We used GeoVisor, for instance, which is a Google product that provides pretty strong isolation of code. So we built a product where you can basically like run arbitrary code inside a container and monitor its output or like get it back in a safe way. I mean, over time it's like evolved into more of like, I think the long-term direction is actually I think more interesting, which is that I think modal as a platform where like I think the core like container infrastructure we offer could actually be like, you know, unbundled from like the client SDK and offer to like other, you know, like we're talking to a couple of like other companies that want to run, you know, through their packages, like run, execute jobs on modal, like kind of programmatically. So that's actually the direction like Sandbox is going. It's like turning into more like a platform for platforms is kind of what I've been thinking about it as.Swyx [00:40:45]: Oh boy. Platform. That's the old Kubernetes line.Erik [00:40:48]: Yeah. Yeah. Yeah. But it's like, you know, like having that ability to like programmatically, you know, create containers and execute them, I think, I think is really cool. And I think it opens up a lot of interesting capabilities that are sort of separate from the like core Python SDK in modal. So I'm really excited about C. It's like one of those features that we kind of released and like, you know, then we kind of look at like what users actually build with it and people are starting to build like kind of crazy things. And then, you know, we double down on some of those things because when we see like, you know, potential new product features and so Sandbox, I think in that sense, it's like kind of in that direction. We found a lot of like interesting use cases in the direction of like platformized container runner.Swyx [00:41:27]: Can you be more specific about what you're double down on after seeing users in action?Erik [00:41:32]: I mean, we're working with like some companies that, I mean, without getting into specifics like that, need the ability to take their users code and then launch containers on modal. And it's not about security necessarily, like they just want to use modal as a back end, right? Like they may already provide like Kubernetes as a back end, Lambda as a back end, and now they want to add modal as a back end, right? And so, you know, they need a way to programmatically define jobs on behalf of their users and execute them. And so, I don't know, that's kind of abstract, but does that make sense? I totally get it.Swyx [00:42:03]: It's sort of one level of recursion to sort of be the Modal for their customers.Erik [00:42:09]: Exactly.Swyx [00:42:10]: Yeah, exactly. And Cloudflare has done this, you know, Kenton Vardar from Cloudflare, who's like the tech lead on this thing, called it sort of functions as a service as a service.Erik [00:42:17]: Yeah, that's exactly right. FaSasS.Swyx [00:42:21]: FaSasS. Yeah, like, I mean, like that, I think any base layer, second layer cloud provider like yourself, compute provider like yourself should provide, you know, it's a mark of maturity and success that people just trust you to do that. They'd rather build on top of you than compete with you. The more interesting thing for me is like, what does it mean to serve a computer like an LLM developer, rather than a human developer, right? Like, that's what a sandbox is to me, that you have to redefine modal to serve a different non-human audience.Erik [00:42:51]: Yeah. Yeah, and I think there's some really interesting people, you know, building very cool things.Swyx [00:42:55]: Yeah. So I don't have an answer, but, you know, I imagine things like, hey, the way you give feedback is different. Maybe you have to like stream errors, log errors differently. I don't really know. Yeah. Obviously, there's like safety considerations. Maybe you have an API to like restrict access to the web. Yeah. I don't think anyone would use it, but it's there if you want it.Erik [00:43:17]: Yeah.Swyx [00:43:18]: Yeah. Any other sort of design considerations? I have no idea.Erik [00:43:21]: With sandboxes?Swyx [00:43:22]: Yeah. Yeah.Erik [00:43:24]: Open-ended question here. Yeah. I mean, no, I think, yeah, the network restrictions, I think, make a lot of sense. Yeah. I mean, I think, you know, long-term, like, I think there's a lot of interesting use cases where like the LLM, in itself, can like decide, I want to install these packages and like run this thing. And like, obviously, for a lot of those use cases, like you want to have some sort of control that it doesn't like install malicious stuff and steal your secrets and things like that. But I think that's what's exciting about the sandbox primitive, is like it lets you do that in a relatively safe way.Alessio [00:43:51]: Do you have any thoughts on the inference wars? A lot of providers are just rushing to the bottom to get the lowest price per million tokens. Some of them, you know, the Sean Randomat, they're just losing money and there's like the physics of it just don't work out for them to make any money on it. How do you think about your pricing and like how much premium you can get and you can kind of command versus using lower prices as kind of like a wedge into getting there, especially once you have model instrumented? What are the tradeoffs and any thoughts on strategies that work?Erik [00:44:23]: I mean, we focus more on like custom models and custom code. And I think in that space, there's like less competition and I think we can have a pricing markup, right? Like, you know, people will always compare our prices to like, you know, the GPU power they can get elsewhere. And so how big can that markup be? Like it never can be, you know, we can never charge like 10x more, but we can certainly charge a premium. And like, you know, for that reason, like we can have pretty good margins. The LLM space is like the opposite, like the switching cost of LLMs is zero. If all you're doing is like straight up, like at least like open source, right? Like if all you're doing is like, you know, using some, you know, inference endpoint that serves an open source model and, you know, some other provider comes along and like offers a lower price, you're just going to switch, right? So I don't know, to me that reminds me a lot of like all this like 15 minute delivery wars or like, you know, like Uber versus Lyft, you know, and like maybe going back even further, like I think a lot about like sort of, you know, flip side of this is like, it's actually a positive side, which is like, I thought a lot about like fiber optics boom of like 98, 99, like the other day, or like, you know, and also like the overinvestment in GPU today. Like, like, yeah, like, you know, I don't know, like in the end, like, I don't think VCs will have the return they expected, like, you know, in these things, but guess who's going to benefit, like, you know, is the consumers, like someone's like reaping the value of this. And that's, I think an amazing flip side is that, you know, we should be very grateful, the fact that like VCs want to subsidize these things, which is, you know, like you go back to fiber optics, like there was an extreme, like overinvestment in fiber optics network in like 98. And no one made money who did that. But consumers, you know, got tremendous benefits of all the fiber optics cables that were led, you know, throughout the country in the decades after. I feel something similar abou

Follow: https://stree.ai/podcast | Sub: https://stree.ai/sub | New episodes every Monday! Dive into part two of our conversation with Eric Sammer as we explore the evolution of stream processing from Hadoop to Kafka and Flink. Eric shares his insights on the transformative journey of data processing technologies and their impact on the industry. Tune in for a compelling look at the past, present, and future of stream processing.

Check out this high-level overview into the Hadoop ecosystem! Want to support us? Become a premium subscriber to The Data Science Interview Prep Podcast: https://podcasters.spotify.com/pod/show/data-science-interview/subscribe

AI is a huge opportunity for businesses. How can organizations seize this opportunity? Well by understanding how AI works, its opportunities and drawbacks, responsible AI and data security. This is exactly what our guest Balaji Ganesan, Co-Founder and CEO of Privacera and our host Punit Bhatia, CEO of FIT4Privacy are talking about in this episode. Take a listen now. KEY CONVERSATION POINTS AI in one word How can businesses combine data governance and AI? How can companies start AI programs Responsible AI framework and policies Data governance and data security Closing ABOUT THE GUEST Balaji Ganesan is CEO and co-founder of Privacera. Before Privacera, Balaji and Privacera co-founder Don Bosco Durai, also founded XA Secure. XA Secure's was acquired by Hortonworks, who contributed the product to the Apache Software Foundation and rebranded as Apache Ranger. Apache Ranger is now deployed in thousands of companies around the world, managing petabytes of data in Hadoop environments. Privacera's product is built on the foundation of Apache Ranger and provides a single pane of glass for securing sensitive data across on-prem and multiple cloud services such as AWS, Azure, Databricks, GCP, Snowflake, and Starburst and more. ABOUT THE HOST Punit Bhatia is one of the leading privacy experts who works independently and has worked with professionals in over 30 countries. Punit works with business and privacy leaders to create an organization culture with high AI & privacy awareness and compliance as a business priority by creating and implementing a AI & privacy strategy and policy. Punit is the author of books “Be Ready for GDPR” which was rated as the best GDPR Book, “AI & Privacy – How to Find Balance”, “Intro To GDPR”, and “Be an Effective DPO”. Punit is a global speaker who has spoken at over 50 global events. Punit is the creator and host of the FIT4PRIVACY Podcast. This podcast has been featured amongst top GDPR and privacy podcasts. As a person, Punit is an avid thinker and believes in thinking, believing, and acting in line with one's value to have joy in life. He has developed the philosophy named ‘ABC for joy of life' which passionately shares. Punit is based out of Belgium, the heart of Europe. RESOURCES Websites www.fit4privacy.com , www.punitbhatia.com, www.privacera.com Podcast https://www.fit4privacy.com/podcast Blog https://www.fit4privacy.com/blog YouTube http://youtube.com/fit4privacy --- Send in a voice message: https://podcasters.spotify.com/pod/show/fit4privacy/message
Summary Building machine learning systems and other intelligent applications are a complex undertaking. This often requires retrieving data from a warehouse engine, adding an extra barrier to every workflow. The RelationalAI engine was built as a co-processor for your data warehouse that adds a greater degree of flexibility in the representation and analysis of the underlying information, simplifying the work involved. In this episode CEO Molham Aref explains how RelationalAI is designed, the capabilities that it adds to your data clouds, and how you can start using it to build more sophisticated applications on your data. Announcements Hello and welcome to the Machine Learning Podcast, the podcast about machine learning and how to bring it from idea to delivery. Your host is Tobias Macey and today I'm interviewing Molham Aref about RelationalAI and the principles behind it for powering intelligent applications Interview Introduction How did you get involved in machine learning? Can you describe what RelationalAI is and the story behind it? On your site you call your product an "AI Co-processor". Can you explain what you mean by that phrase? What are the primary use cases that you address with the RelationalAI product? What are the types of solutions that teams might build to address those problems in the absence of something like the RelationalAI engine? Can you describe the system design of RelationalAI? How have the design and goals of the platform changed since you first started working on it? For someone who is using RelationalAI to address a business need, what does the onboarding and implementation workflow look like? What is your design philosophy for identifying the balance between automating the implementation of certain categories of application (e.g. NER) vs. providing building blocks and letting teams assemble them on their own? What are the data modeling paradigms that teams should be aware of to make the best use of the RKGS platform and Rel language? What are the aspects of customer education that you find yourself spending the most time on? What are some of the most under-utilized or misunderstood capabilities of the RelationalAI platform that you think deserve more attention? What are the most interesting, innovative, or unexpected ways that you have seen the RelationalAI product used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on RelationalAI? When is RelationalAI the wrong choice? What do you have planned for the future of RelationalAI? Contact Info LinkedIn (https://www.linkedin.com/in/molham/) Parting Question From your perspective, what is the biggest barrier to adoption of machine learning today? Closing Announcements Thank you for listening! Don't forget to check out our other shows. The Data Engineering Podcast (https://www.dataengineeringpodcast.com) covers the latest on modern data management. Podcast.__init__ () covers the Python language, its community, and the innovative ways it is being used. Visit the site (https://www.themachinelearningpodcast.com) to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email hosts@themachinelearningpodcast.com (mailto:hosts@themachinelearningpodcast.com)) with your story. To help other people find the show please leave a review on iTunes (https://podcasts.apple.com/us/podcast/the-machine-learning-podcast/id1626358243) and tell your friends and co-workers. Links RelationalAI (https://relational.ai/) Snowflake (https://www.snowflake.com/en/) AI Winter (https://en.wikipedia.org/wiki/AI_winter) BigQuery (https://cloud.google.com/bigquery) Gradient Descent (https://en.wikipedia.org/wiki/Gradient_descent) B-Tree (https://en.wikipedia.org/wiki/B-tree) Navigational Database (https://en.wikipedia.org/wiki/Navigational_database) Hadoop (https://hadoop.apache.org/) Teradata (https://www.teradata.com/) Worst Case Optimal Join (https://relational.ai/blog/worst-case-optimal-join-algorithms-techniques-results-and-open-problems) Semantic Query Optimization (https://relational.ai/blog/semantic-optimizer) Relational Algebra (https://en.wikipedia.org/wiki/Relational_algebra) HyperGraph (https://en.wikipedia.org/wiki/Hypergraph) Linear Algebra (https://en.wikipedia.org/wiki/Linear_algebra) Vector Database (https://en.wikipedia.org/wiki/Vector_database) Pathway (https://pathway.com/) Data Engineering Podcast Episode (https://www.dataengineeringpodcast.com/pathway-database-that-thinks-episode-334/) Pinecone (https://www.pinecone.io/) Data Engineering Podcast Episode (https://www.dataengineeringpodcast.com/pinecone-vector-database-similarity-search-episode-189/) The intro and outro music is from Hitman's Lovesong feat. Paola Graziano (https://freemusicarchive.org/music/The_Freak_Fandango_Orchestra/Tales_Of_A_Dead_Fish/Hitmans_Lovesong/) by The Freak Fandango Orchestra (http://freemusicarchive.org/music/The_Freak_Fandango_Orchestra/)/CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0/)

AI Today Podcast: Artificial Intelligence Insights, Experts, and Opinion
Hadoop and MapReduce changed the world of big data. And data is the heart of AI, so it should come as no surprise that talk about big data in the context of AI. In this episode of the AI Today podcast hosts Kathleen Walch and Ron Schmelzer define the terms Hadoop, MapReduce, explain how these terms relate to AI and why it's important to know about them. Continue reading AI Today Podcast: AI Glossary Series – Hadoop, MapReduce at Cognilytica.

This is Zack Fuss. Today I am joined by Yanev Suissa, Managing Partner at SineWave Ventures, to break down the private company Databricks. Born out of a UC Berkeley research lab in 2013, Databricks has grown rapidly, and after 50% growth this summer, it was rumored to have last raised at a $43 billion valuation. In the most simple terms, Databricks provides tools for ingesting, transforming, and analyzing large sets of data from multiple sources in multiple formats in order to inform business and engineering decisions. Databricks is on a crash course with Snowflake to amass market share. In this conversation, we explore the nuances of structured and unstructured data, discuss data lakes, and what it entails to get "Hadooped." Please enjoy this breakdown of Databricks. Interested in hiring from the Colossus Community? Click here. For the full show notes, transcript, and links to the best content to learn more, check out the episode page here. ----- This episode is brought to you by Tegus. Tegus is the modern research platform for leading investors, and provider of Canalyst. Tired of calculating fully-diluted shares outstanding? Access every publicly-reported datapoint and industry-specific KPI through their database of over 4,000 driveable global models handbuilt by a team of sector-focused analysts, 35+ industry comp sheets, and Excel add-ins that let you use their industry-leading data in your own spreadsheets. Tegus' models automatically update each quarter, including hard to calculate KPIs like stock-based compensation and organic growth rates, empowering investors to bypass the friction of sourcing, building and updating models. Make efficiency your competitive advantage and take back your time today. As a listener, you can trial Canalyst by Tegus for free by visiting tegus.co/patrick. ----- Business Breakdowns is a property of Colossus, LLC. For more episodes of Business Breakdowns, visit joincolossus.com/episodes. Stay up to date on all our podcasts by signing up to Colossus Weekly, our quick dive every Sunday highlighting the top business and investing concepts from our podcasts and the best of what we read that week. Sign up here. Follow us on Twitter: @JoinColossus | @patrick_oshag | @jspujji | @zbfuss | @ReustleMatt | @domcooke Show Notes: (00:02:32) - (First Question) - What Databricks is and why it is so successful (00:04:38) - Real world examples of how customers use Databricks (00:07:23) - How issues were handled historically before Databricks was available (00:08:39) - Key examples of what helped accelerate Databricks' success (00:10:52) - Databricks revenue model and how it converts into bottomline (00:12:13) - How Databricks competes with competitors like Snowflake (00:14:11) - Competition versus symbiosis when compared to large organizations (00:14:11) - The overall size of Databricks as a business (00:18:09) - Costs incurred when using a database service like Databricks (00:19:47) - The founding story of Databricks (00:22:53) - When SineWave recognized the database's potential (00:24:29) - The importance of partnerships and how they help grow the business (00:27:07) - Legacy solutions that they are disintermediating or replacing in their growth (00:27:57) - What being Hadoop'd means (00:21:50) - A breakdown of the complexity behind switching to different database providers (00:32:07) - The success of these businesses breaking into legacy regulated industries (00:34:47) - Why AI is so impactful to the database (00:37:40) - How AI is helping these businesses go to market with their software (00:39:50) - Democratization of data access and businesses taking the opposite approach (00:43:00) - Key reasons for investing in Databricks and potential risks to be considered (00:46:12) - Lessons learned from studying Databricks Learn more about your ad choices. Visit megaphone.fm/adchoices

In 2002, Hadoop hit the scene, and quickly became a media darling. Twenty years later, typing the term into a search engine will return questions about its continued relevance—or possible lack thereof.Is Hadoop still important? Where is it most visible today? The Compiler team dives hard into the project, and how it forever changed the way we look at data.
AI - you know it's the big new thing that has won all the buzz in today's tech world.Does it deserve it?Hear a loud “yes” in this podcast with Saroop Bharwani, CEO of Senso.ai and a co-creator of CU Copilot, a consortium of AI early adopter credit unions that are joining together to learn how to put AI to transformative uses in their institutions.A half dozen credit unions already engage in CU Copilot and Bahrwani says more are coming and that is a good thing because credit unions are in a position to grab a dramatic lead in AI adoption and that will help the industry stay highly competitive through the years of change that are on the horizon.Also on the show is Joey Rudisill, CIO at $500 million Central Willamette Credit Union which is already a consortium member. On the show Joey gives an incisive perspective on what AI adoption is like on the ground floor of a credit union.Here is the link to CuCopilot: http://cucopilot.com/You want to sign up for the consortium? Here's a link.You want to see the videos on AI that are mentioned in the show? Here's another link.Know this: you will be hearing more and more about AI and the plain truth is that it is triggering a revolution that will utterly change how a lot of work gets done. You can't close your eyes to this. At least you can't if you want to stay relevant.Listen up.Like what you are hearing? Find out how you can help sponsor this podcast here. Very affordable sponsorship packages are available. Email rjmcgarvey@gmail.com And like this podcast on whatever service you use to stream it. That matters. Find out more about CU2.0 and the digital transformation of credit unions here. It's a journey every credit union needs to take. Pronto

Welcome to the "Secrets of #Fail," a new pod storm series hosted by Matt Brown. In this series of 2023, Matt dives deep into the world of failures and lessons learned along the way from high-net-worth individuals. Join Matt as he dives into the world of failures and lessons.Series: Secret of #FailDave is one of the co-founders of AtScale and is the Chief Technology Officer. Prior to AtScale, he was VP of Engineering at Klout and at Yahoo!, where he built the world's largest multi-dimensional cube for BI on Hadoop. Mariani is a big data visionary and serial entrepreneurGet an interview on the Matt Brown Show: www.mattbrownshow.comSupport the show
Highlights from this week's conversation include:A.J.'s background and journey in data (2:23)Challenges with Hadoop ecosystem (8:50)Starting InfinyOn and the need for innovation (10:02)Challenges with Kafka and Microservices (14:01)Real-time data streaming for IoT devices (19:28)Paradigm shift to real-time data processing (22:17)Benefits of Rust (29:45)Web Assembly and Platform Features (36:29)Analytics and Event Correlation (40:16)Real-time data processing (47:03)ETL vs ELP (52:20)Final thoughts and takeaways (57:07)The Data Stack Show is a weekly podcast powered by RudderStack, the CDP for developers. Each week we'll talk to data engineers, analysts, and data scientists about their experience around building and maintaining data infrastructure, delivering data and data products, and driving better outcomes across their businesses with data.RudderStack helps businesses make the most out of their customer data while ensuring data privacy and security. To learn more about RudderStack visit rudderstack.com.

Aki is an advisor to Invisible focusing on Artificial Intelligence and helping Invisible to do market validation. Find Aki here on Twitter: https://twitter.com/AkiBalogh Show Notes How will AI change the peer review process? The pyramid of ideas evolves from knowledge to wisdom. The internet has significantly opened up access to data. Ideas are networks that are supported by data. Advanced AI is capable of processing and analyzing large amounts of data. AI can extract useful information from data, but it's still humans who synthesize wisdom from it. The individual is knowledgeable about the peer review system. There's a high level of analysis involved in the process. The scientific publishing sector was greatly impacted by the emergence of open-source journals. Why is the integration of AI in certain fields still a distant prospect? In marketing content, there's a technical component. However, the essential need is for relevant content. AI is creating a different game in various sectors. AI has the potential to replace unskilled labor and augment our base capabilities. AI could help lower the costs of education. Chegg's earnings have significantly dropped. If the technology for self-driving cars works well, it could revolutionize transport. AI developed and used within legal frameworks is safer. The developing world could greatly benefit from educational AI. OpenAI recently published an epilogue. The human brain functions like a parallel system, capable of data analysis and creativity. Aki Balogh got into AI due to his interest in data analysis, his computer science and business degrees, and his experience in management consulting. The emergence of Hadoop has enabled the handling of very large data sets. The challenge now is figuring out what we can do with all this data. Generative AI and tools like Spark are revolutionizing data analysis. The introduction of AI in education may lead to inevitable job losses. Education is the only solution to this problem. In 2009, I was working in Abu Dhabi under tough conditions. Someone gave me a computer and suggested I use Khan Academy, which is free. The use of AI, like GPT-4, can empower even non-technical individuals. The challenge of integrating new technologies into a system remains. The enemy is wasted human potential. If we apply ourselves, we can figure out everything. The idea of writing as a cyborg brings into question the limitations of data. The omnipresent force of technology can sometimes overwhelm our nervous systems. We need better strategies to consume this tech. Market Muse attempted to diagram the whole channel to map the entire value chain of a product. The goal of AGI (Artificial General Intelligence) is a contentious topic. Every person has multiple talents that can be utilized. AI safety is a critical concern as we develop more sophisticated AI. AI safety can be likened to raising a child, with an emphasis on preventing an "Oedipus complex." The singularity concept involves humans and AI merging, much like a Borg. AI can significantly contribute to reducing waste and improving efficiency. AI might help us reach our capacity for progress faster. The role of VCs is crucial in the growth of new tech companies. Values come from wisdom, which we hope to instill in our children. It's not the strongest who survive, but the most adaptable. The potential for building infrastructure on Bitcoin is being explored.

https://fellow.app/supermanagers/nathan-trueblood-practicing-transformational-leadership-how-to-drive-change-through-influence/ Transformational leadership has a positive effect on mental health. Leaders who adopt a transformational approach inspire others by encouraging team members to engage in creative thinking and tailoring their approach to the individual needs of each employee. In episode #147, Nathan explains how to drive change within organizations by practicing transformational leadership. Nathan Trueblood has many years of experience including working at companies like Box, Yahoo, EMC, Hadoop, OpenStack. He's a technologist, product leader, founder and mentor. Today, he is the founder of Trueblood Advisory. Tune in to hear all about Nathan's leadership journey and the lessons learned along the way! . . . Like this episode? Be sure to leave a ⭐️⭐️⭐️⭐️⭐️ review and share the podcast with your colleagues. . . . TIME-STAMPED SHOW NOTES: [04:45] Distributed systems [11:25] Delegating a problem versus task [16:15] What is transformational leadership? [20:46] Transformational leaderships and product teams [24:17] Leading through influence [32:11] Coalition of the willing [37:46] Design alliances [40:40] Doing a calendar audit 44:57] Parting words of advice RESOURCES MENTIONED IN THIS EPISODE: Read Daisy Grewall's article Subscribe to the Supermanagers TLDR newsletter
Highlights from this week's conversation include:Dhruba's journey into the data space (2:02)The impact of Hadoop on the industry (3:37)Dhruba's work in the early days of the Facebook team (7:54)Building and implementing RocksDB (14:33)Stories with Mark Zuckerberg at Facebook (24:25)The next evolution in storage hardware (26:14)How Rockset is different from other real-time platforms (33:13)Going from a key value store to an index (37:15)Where does Rockset go from here? (44:59)The success of RocksDB as an open source project (49:11)How do we properly steward real-time technology for impact (51:17)Final thoughts and takeaways (56:18)The Data Stack Show is a weekly podcast powered by RudderStack, the CDP for developers. Each week we'll talk to data engineers, analysts, and data scientists about their experience around building and maintaining data infrastructure, delivering data and data products, and driving better outcomes across their businesses with data.RudderStack helps businesses make the most out of their customer data while ensuring data privacy and security. To learn more about RudderStack visit rudderstack.com.
Summary Cloud data warehouses have unlocked a massive amount of innovation and investment in data applications, but they are still inherently limiting. Because of their complete ownership of your data they constrain the possibilities of what data you can store and how it can be used. Projects like Apache Iceberg provide a viable alternative in the form of data lakehouses that provide the scalability and flexibility of data lakes, combined with the ease of use and performance of data warehouses. Ryan Blue helped create the Iceberg project, and in this episode he rejoins the show to discuss how it has evolved and what he is doing in his new business Tabular to make it even easier to implement and maintain. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Hey there podcast listener, are you tired of dealing with the headache that is the 'Modern Data Stack'? We feel your pain. It's supposed to make building smarter, faster, and more flexible data infrastructures a breeze. It ends up being anything but that. Setting it up, integrating it, maintaining it—it's all kind of a nightmare. And let's not even get started on all the extra tools you have to buy to get it to do its thing. But don't worry, there is a better way. TimeXtender takes a holistic approach to data integration that focuses on agility rather than fragmentation. By bringing all the layers of the data stack together, TimeXtender helps you build data solutions up to 10 times faster and saves you 70-80% on costs. If you're fed up with the 'Modern Data Stack', give TimeXtender a try. Head over to timextender.com/dataengineering where you can do two things: watch us build a data estate in 15 minutes and start for free today. Your host is Tobias Macey and today I'm interviewing Ryan Blue about the evolution and applications of the Iceberg table format and how he is making it more accessible at Tabular Interview Introduction How did you get involved in the area of data management? Can you describe what Iceberg is and its position in the data lake/lakehouse ecosystem? Since it is a fundamentally a specification, how do you manage compatibility and consistency across implementations? What are the notable changes in the Iceberg project and its role in the ecosystem since our last conversation October of 2018? Around the time that Iceberg was first created at Netflix a number of alternative table formats were also being developed. What are the characteristics of Iceberg that lead teams to adopt it for their lakehouse projects? Given the constant evolution of the various table formats it can be difficult to determine an up-to-date comparison of their features, particularly earlier in their development. What are the aspects of this problem space that make it so challenging to establish unbiased and comprehensive comparisons? For someone who wants to manage their data in Iceberg tables, what does the implementation look like? How does that change based on the type of query/processing engine being used? Once a table has been created, what are the capabilities of Iceberg that help to support ongoing use and maintenance? What are the most interesting, innovative, or unexpected ways that you have seen Iceberg used? What are the most interesting, unexpected, or challenging lessons that you have learned while working on Iceberg/Tabular? When is Iceberg/Tabular the wrong choice? What do you have planned for the future of Iceberg/Tabular? Contact Info LinkedIn (https://www.linkedin.com/in/rdblue/) rdblue (https://github.com/rdblue) on GitHub Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today? Closing Announcements Thank you for listening! Don't forget to check out our other shows. Podcast.__init__ (https://www.pythonpodcast.com) covers the Python language, its community, and the innovative ways it is being used. The Machine Learning Podcast (https://www.themachinelearningpodcast.com) helps you go from idea to production with machine learning. Visit the site (https://www.dataengineeringpodcast.com) to subscribe to the show, sign up for the mailing list, and read the show notes. If you've learned something or tried out a project from the show then tell us about it! Email hosts@dataengineeringpodcast.com (mailto:hosts@dataengineeringpodcast.com)) with your story. To help other people find the show please leave a review on Apple Podcasts (https://podcasts.apple.com/us/podcast/data-engineering-podcast/id1193040557) and tell your friends and co-workers Links Iceberg (https://iceberg.apache.org/) Podcast Episode (https://www.dataengineeringpodcast.com/iceberg-with-ryan-blue-episode-52/) Hadoop (https://hadoop.apache.org/) Data Lakehouse (https://www.forbes.com/sites/bernardmarr/2022/01/18/what-is-a-data-lakehouse-a-super-simple-explanation-for-anyone/) ACID == Atomic, Consistent, Isolated, Durable (https://en.wikipedia.org/wiki/ACID) Apache Hive (https://hive.apache.org/) Apache Impala (https://impala.apache.org/) Bodo (https://www.bodo.ai/) Podcast Episode (https://www.dataengineeringpodcast.com/bodo-parallel-data-processing-python-episode-223/) StarRocks (https://www.starrocks.io/) Dremio (https://www.dremio.com/) Podcast Episode (https://www.dataengineeringpodcast.com/dremio-open-data-lakehouse-episode-333/) DDL == Data Definition Language (https://en.wikipedia.org/wiki/Data_definition_language) Trino (https://trino.io/) PrestoDB (https://prestodb.io/) Apache Hudi (https://hudi.apache.org/) Podcast Episode (https://www.dataengineeringpodcast.com/hudi-streaming-data-lake-episode-209/) dbt (https://www.getdbt.com/) Apache Flink (https://flink.apache.org/) TileDB (https://tiledb.com/) Podcast Episode (https://www.dataengineeringpodcast.com/tiledb-universal-data-engine-episode-146/) CDC == Change Data Capture (https://en.wikipedia.org/wiki/Change_data_capture) Substrait (https://substrait.io/) The intro and outro music is from The Hug (http://freemusicarchive.org/music/The_Freak_Fandango_Orchestra/Love_death_and_a_drunken_monkey/04_-_The_Hug) by The Freak Fandango Orchestra (http://freemusicarchive.org/music/The_Freak_Fandango_Orchestra/) / CC BY-SA (http://creativecommons.org/licenses/by-sa/3.0/)
About RamDr. Ram Sriharsha held engineering, product management, and VP roles at the likes of Yahoo, Databricks, and Splunk. At Yahoo, he was both a principal software engineer and then research scientist; at Databricks, he was the product and engineering lead for the unified analytics platform for genomics; and, in his three years at Splunk, he played multiple roles including Sr Principal Scientist, VP Engineering and Distinguished Engineer.Links Referenced: Pinecone: https://www.pinecone.io/ XKCD comic: https://www.explainxkcd.com/wiki/index.php/1425:_Tasks TranscriptAnnouncer: Hello, and welcome to Screaming in the Cloud with your host, Chief Cloud Economist at The Duckbill Group, Corey Quinn. This weekly show features conversations with people doing interesting work in the world of cloud, thoughtful commentary on the state of the technical world, and ridiculous titles for which Corey refuses to apologize. This is Screaming in the Cloud.Corey: This episode is sponsored in part by our friends at Chronosphere. Tired of observability costs going up every year without getting additional value? Or being locked into a vendor due to proprietary data collection, querying, and visualization? Modern-day, containerized environments require a new kind of observability technology that accounts for the massive increase in scale and attendant cost of data. With Chronosphere, choose where and how your data is routed and stored, query it easily, and get better context and control. 100% open-source compatibility means that no matter what your setup is, they can help. Learn how Chronosphere provides complete and real-time insight into ECS, EKS, and your microservices, wherever they may be at snark.cloud/chronosphere that's snark.cloud/chronosphere.Corey: This episode is brought to you in part by our friends at Veeam. Do you care about backups? Of course you don't. Nobody cares about backups. Stop lying to yourselves! You care about restores, usually right after you didn't care enough about backups. If you're tired of the vulnerabilities, costs, and slow recoveries when using snapshots to restore your data, assuming you even have them at all living in AWS-land, there is an alternative for you. Check out Veeam, that's V-E-E-A-M for secure, zero-fuss AWS backup that won't leave you high and dry when it's time to restore. Stop taking chances with your data. Talk to Veeam. My thanks to them for sponsoring this ridiculous podcast.Corey: Welcome to Screaming in the Cloud. I'm Corey Quinn. Today's promoted guest episode is brought to us by our friends at Pinecone and they have given their VP of Engineering and R&D over to suffer my various sling and arrows, Ram Sriharsha. Ram, thank you for joining me.Ram: Corey, great to be here. Thanks for having me.Corey: So, I was immediately intrigued when I wound up seeing your website, pinecone.io because it says right at the top—at least as of this recording—in bold text, “The Vector Database.” And if there's one thing that I love, it is using things that are not designed to be databases as databases, or inappropriately referring to things—be they JSON files or senior engineers—as databases as well. What is a vector database?Ram: That's a great question. And we do use this term correctly, I think. You can think of customers of Pinecone as having all the data management problems that they have with traditional databases; the main difference is twofold. One is there is a new data type, which is vectors. Vectors, you can think of them as arrays of floats, floating point numbers, and there is a new pattern of use cases, which is search.And what you're trying to do in vector search is you're looking for the nearest, the closest vectors to a given query. So, these two things fundamentally put a lot of stress on traditional databases. So, it's not like you can take a traditional database and make it into a vector database. That is why we coined this term vector database and we are building a new type of vector database. But fundamentally, it has all the database challenges on a new type of data and a new query pattern.Corey: Can you give me an example of what, I guess, an idealized use case would be of what the data set might look like and what sort of problem you would have in a vector database would solve?Ram: A very great question. So, one interesting thing is there's many, many use cases. I'll just pick the most natural one which is text search. So, if you're familiar with the Elastic or any other traditional text search engines, you have pieces of text, you index them, and the indexing that you do is traditionally an inverted index, and then you search over this text. And what this sort of search engine does is it matches for keywords.So, if it finds a keyword match between your query and your corpus, it's going to retrieve the relevant documents. And this is what we call text search, right, or keyword search. You can do something similar with technologies like Pinecone, but what you do here is instead of searching our text, you're searching our vectors. Now, where do these vectors come from? They come from taking deep-learning models, running your text through them, and these generate these things called vector embeddings.And now, you're taking a query as well, running them to deep-learning models, generating these query embeddings, and looking for the closest record embeddings in your corpus that are similar to the query embeddings. This notion of proximity in this space of vectors tells you something about semantic similarity between the query and the text. So suddenly, you're going beyond keyword search into semantic similarity. An example is if you had a whole lot of text data, and maybe you were looking for ‘soda,' and you were doing keyword search. Keyword search will only match on variations of soda. It will never match ‘Coca-Cola' because Coca-Cola and soda have nothing to do with each other.Corey: Or Pepsi, or pop, as they say in the American Midwest.Ram: Exactly.Corey: Yeah.Ram: Exactly. However, semantic search engines can actually match the two because they're matching for intent, right? If they find in this piece of text, enough intent to suggest that soda and Coca-Cola or Pepsi or pop are related to each other, they will actually match those and score them higher. And you're very likely to retrieve those sort of candidates that traditional search engines simply cannot. So, this is a canonical example, what's called semantic search, and it's known to be done better by these other vector search engines. There are also other examples in say, image search. Just if you're looking for near duplicate images, you can't even do this today without a technology like vector search.Corey: What is the, I guess, translation or conversion process of existing dataset into something that a vector database could use? Because you mentioned it was an array of floats was the natural vector datatype. I don't think I've ever seen even the most arcane markdown implementation that expected people to wind up writing in arrays of floats. What does that look like? How do you wind up, I guess, internalizing or ingesting existing bodies of text for your example use case?Ram: Yeah, this is a very great question. This used to be a very hard problem and what has happened over the last several years in deep-learning literature, as well as in deep-learning as a field itself, is that there have been these large, publicly trained models, examples will be OpenAI, examples will be the models that are available in Hugging Face like Cohere, and a large number of these companies have come forward with very well trained models through which you can pass pieces of text and get these vectors. So, you no longer have to actually train these sort of models, you don't have to really have the expertise to deeply figured out how to take pieces of text and build these embedding models. What you can do is just take a stock model, if you're familiar with OpenAI, you can just go to OpenAIs homepage and pick a model that works for you, Hugging Face models, and so on. There's a lot of literature to help you do this.Sophisticated customers can also do something called fine-tuning, which is built on top of these models to fine-tune for their use cases. The technology is out there already, there's a lot of documentation available. Even Pinecone's website has plenty of documentation to do this. Customers of Pinecone do this [unintelligible 00:07:45], which is they take piece of text, run them through either these pre-trained models or through fine-tuned models, get the series of floats which represent them, vector embeddings, and then send it to us. So, that's the workflow. The workflow is basically a machine-learning pipeline that either takes a pre-trained model, passes them through these pieces of text or images or what have you, or actually has a fine-tuning step in it.Corey: Is that ingest process something that not only benefits from but also requires the use of a GPU or something similar to that to wind up doing the in-depth, very specific type of expensive math for data ingestion?Ram: Yes, very often these run on GPUs. Sometimes, depending on budget, you may have compressed models or smaller models that run on CPUs, but most often they do run on GPUs, most often, we actually find people make just API calls to services that do this for them. So, very often, people are actually not deploying these GPU models themselves, they are maybe making a call to Hugging Face's service, or to OpenAI's service, and so on. And by the way, these companies also democratized this quite a bit. It was much, much harder to do this before they came around.Corey: Oh, yeah. I mean, I'm reminded of the old XKCD comic from years ago, which was, “Okay, I want to give you a picture. And I want you to tell me it was taken within the boundaries of a national park.” Like, “Sure. Easy enough. Geolocation information is attached. It'll take me two hours.” “Cool. And I also want you to tell me if it's a picture of a bird.” “Okay, that'll take five years and a research team.”And sure enough, now we can basically do that. The future is now and it's kind of wild to see that unfolding in a human perceivable timespan on these things. But I guess my question now is, so that is what a vector database does? What does Pinecone specifically do? It turns out that as much as I wish it were otherwise, not a lot of companies are founded on, “Well, we have this really neat technology, so we're just going to be here, well, in a foundational sense to wind up ensuring the uptake of that technology.” No, no, there's usually a monetization model in there somewhere. Where does Pinecone start, where does it stop, and how does it differentiate itself from typical vector databases? If such a thing could be said to exist yet.Ram: Such a thing doesn't exist yet. We were the first vector database, so in a sense, building this infrastructure, scaling it, and making it easy for people to operate it in a SaaS fashion is our primary core product offering. On top of that, this very recently started also enabling people who have who actually have raw text to not just be able to get value from these vector search engines and so on, but also be able to take advantage of traditional what we call keyword search or sparse retrieval and do a combined search better, in Pinecone. So, there's value-add on top of this that we do, but I would say the core of it is building a SaaS managed platform that allows people to actually easily store as data, scale it, query it in a way that's very hands off and doesn't require a lot of tuning or operational burden on their side. This is, like, our core value proposition.Corey: Got it. There's something to be said for making something accessible when previously it had only really been available to people who completed the Hello World tutorial—which generally resembled a doctorate at Berkeley or Waterloo or somewhere else—and turn it into something that's fundamentally, click the button. Where on that, I guess, a spectrum of evolution do you find that Pinecone is today?Ram: Yeah. So, you know, prior to Pinecone, we didn't really have this notion of a vector database. For several years, we've had libraries that are really good that you can pre-train on your embeddings, generate this thing called an index, and then you can search over that index. There is still a lot of work to be done even to deploy that and scale it and operate it in production and so on. Even that was not being, kind of, offered as a managed service before.What Pinecone does which is novel, is you no longer have to have this pre-training be done by somebody, you no longer have to worry about when to retrain your indexes, what to do when you have new data, what to do when there is deletions, updates, and the usual data management operations. You can just think of this is, like, a database that you just throw your data in. It does all the right things for you, you just worry about querying. This has never existed before, right? This is—it's not even like we are trying to make the operational part of something easier. It is that we are offering something that hasn't existed before, at the same time, making it operationally simple.So, we're solving two problems, which is we building a better database that hasn't existed before. So, if you really had this sort of data management problems and you wanted to build an index that was fresh that you didn't have to super manually tune for your own use cases, that simply couldn't have been done before. But at the same time, we are doing all of this in a cloud-native fashion; it's easy for you to just operate and not worry about.Corey: You've said that this hasn't really been done before, but this does sound like it is more than passingly familiar specifically to the idea of nearest neighbor search, which has been around since the '70s in a bunch of different ways. So, how is it different? And let me of course, ask my follow-up to that right now: why is this even an interesting problem to start exploring?Ram: This is a great question. First of all, nearest neighbor search is one of the oldest forms of machine learning. It's been known for decades. There's a lot of literature out there, there are a lot of great libraries as I mentioned in the passing before. All of these problems have primarily focused on static corpuses. So basically, you have a set of some amount of data, you want to create an index out of it, and you want to query it.A lot of literature has focused on this problem. Even there, once you go from small number of dimensions to large number of dimensions, things become computationally far more challenging. So, traditional nearest neighbor search actually doesn't scale very well. What do I mean by large number of dimensions? Today, deep-learning models that produce image representations typically operate in 2048 dimensions of photos [unintelligible 00:13:38] dimensions. Some of the OpenAI models are even 10,000 dimensional and above. So, these are very, very large dimensions.Most of the literature prior to maybe even less than ten years back has focused on less than ten dimensions. So, it's like a scale apart in dealing with small dimensional data versus large dimensional data. But even as of a couple of years back, there hasn't been enough, if any, focus on what happens when your data rapidly evolves. For example, what happens when people add new data? What happens if people delete some data? What happens if your vectors get updated? These aren't just theoretical problems; they happen all the time. Customers of ours face this all the time.In fact, the classic example is in recommendation systems where user preferences change all the time, right, and you want to adapt to that, which means your user vectors change constantly. When even these sort of things change constantly, you want your index to reflect it because you want your queries to catch on to the most recent data. [unintelligible 00:14:33] have to reflect the recency of your data. This is a solved problem for traditional databases. Relational databases are great at solving this problem. A lot of work has been done for decades to solve this problem really well.This is a fundamentally hard problem for vector databases and that's one of the core focus areas [unintelligible 00:14:48] painful. Another problem that is hard for these sort of databases is simple things like filtering. For example, you have a corpus of say product images and you want to only look at images that maybe are for the Fall shopping line, right? Seems like a very natural query. Again, databases have known and solved this problem for many, many years.The moment you do nearest neighbor search with these sort of constraints, it's a hard problem. So, it's just the fact that nearest neighbor search and lots of research in this area has simply not focused on what happens to that, so those are of techniques when combined with data management challenges, filtering, and all the traditional challenges of a database. So, when you start doing that you enter a very novel area to begin with.Corey: This episode is sponsored in part by our friends at Redis, the company behind the incredibly popular open-source database. If you're tired of managing open-source Redis on your own, or if you are looking to go beyond just caching and unlocking your data's full potential, these folks have you covered. Redis Enterprise is the go-to managed Redis service that allows you to reimagine how your geo-distributed applications process, deliver and store data. To learn more from the experts in Redis how to be real-time, right now, from anywhere, visit snark.cloud/redis. That's snark dot cloud slash R-E-D-I-S.Corey: So, where's this space going, I guess is sort of the dangerous but inevitable question I have to ask. Because whenever you talk to someone who is involved in a very early stage of what is potentially a transformative idea, it's almost indistinguishable from someone who is whatever the polite term for being wrapped around their own axle is, in a technological sense. It's almost a form of reverse Schneier's Law of anyone can create an encryption algorithm that they themselves cannot break. So, the possibility that this may come back to bite us in the future if it turns out that this is not potentially the revelation that you see it as, where do you see the future of this going?Ram: Really great question. The way I think about it is, and the reason why I keep going back to databases and these sort of ideas is, we have a really great way to deal with structured data and structured queries, right? This is the evolution of the last maybe 40, 50 years is to come up with relational databases, come up with SQL engines, come up with scalable ways of running structured queries on large amounts of data. What I feel like this sort of technology does is it takes it to the next level, which is you can actually ask unstructured questions on unstructured data, right? So, even the couple of examples we just talked about, doing near duplicate detection of images, that's a very unstructured question. What does it even mean to say that two images are nearly duplicate of each other? I couldn't even phrase it as kind of a concrete thing. I certainly cannot write a SQL statement for it, but I cannot even phrase it properly.With these sort of technologies, with the vector embeddings, with deep learning and so on, you can actually mathematically phrase it, right? The mathematical phrasing is very simple once you have the right representation that understands your image as a vector. Two images are nearly duplicate if they are close enough in the space of vectors. Suddenly you've taken a problem that was even hard to express, let alone compute, made it precise to express, precise to compute. This is going to happen not just for images, not just for semantic search, it's going to happen for all sorts of unstructured data, whether it's time series, where it's anomaly detection, whether it's security analytics, and so on.I actually think that fundamentally, a lot of fields are going to get disrupted by this sort of way of thinking about things. We are just scratching the surface here with semantic search, in my opinion.Corey: What is I guess your barometer for success? I mean, if I could take a very cynical point of view on this, it's, “Oh, well, whenever there's a managed vector database offering from AWS.” They'll probably call it Amazon Basics Vector or something like that. Well, that is a—it used to be a snarky observation that, “Oh, we're not competing, we're just validating their market.” Lately, with some of their competitive database offerings, there's a lot more truth to that than I suspect AWS would like.Their offerings are nowhere near as robust as what they pretend to be competing against. How far away do you think we are from the larger cloud providers starting to say, “Ah, we got the sense there was money in here, so we're launching an entire service around this?”Ram: Yeah. I mean, this is a—first of all, this is a great question. There's always something that's constantly, things that any innovator or disrupter has to be thinking about, especially these days. I would say that having a multi-year head, start in the use cases, in thinking about how this system should even look, what sort of use cases should it [unintelligible 00:19:34], what the operating points for the [unintelligible 00:19:37] database even look like, and how to build something that's cloud-native and scalable, is very hard to replicate. Meaning if you look at what we have already done and kind of tried to base the architecture of that, you're probably already a couple of years behind us in terms of just where we are at, right, not just in the architecture, but also in the use cases in where this is evolving forward.That said, I think it is, for all of these companies—and I would put—for example, Snowflake is a great example of this, which is Snowflake needn't have existed if Redshift had done a phenomenal job of being cloud-native, right, and kind of done that before Snowflake did it. In hindsight, it seems like it's obvious, but when Snowflake did this, it wasn't obvious that that's where everything was headed. And Snowflake built something that's very technologically innovative, in a sense that it's even now hard to replicate. Plus, it takes a long time to replicate something like that. I think that's where we are at.If Pinecone does its job really well and if we simply execute efficiently, it's very hard to replicate that. So, I'm not super worried about cloud providers, to be honest, in this space, I'm more worried about our execution.Corey: If it helps anything, I'm not very deep into your specific area of the world, obviously, but I am optimistic when I hear people say things like that. Whenever I find folks who are relatively early along in their technological journey being very concerned about oh, the large cloud provider is going to come crashing in, it feels on some level like their perspective is that they have one weird trick, and they were able to crack that, but they have no defensive mode because once someone else figures out the trick, well, okay, now we're done. The idea of sustained and lasting innovation in a space, I think, is the more defensible position to take, with the counterargument, of course, that that's a lot harder to find.Ram: Absolutely. And I think for technologies like this, that's the only solution, which is, if you really want to avoid being disrupted by cloud providers, I think that's the way to go.Corey: I want to talk a little bit about your own background. Before you wound up as the VP of R&D over at Pinecone, you were in a bunch of similar… I guess, similar styled roles—if we'll call it that—at Yahoo, Databricks, and Splunk. I'm curious as to what your experience in those companies wound up impressing on you that made you say, “Ah, that's great and all, but you know what's next? That's right, vector databases.” And off, you went to Pinecone. What did you see?Ram: So, first of all, in was some way or the other, I have been involved in machine learning and systems and the intersection of these two for maybe the last decade-and-a-half. So, it's always been something, like, in the in between the two and that's been personally exciting to me. So, I'm kind of very excited by trying to think about new type of databases, new type of data platforms that really leverages machine learning and data. This has been personally exciting to me. I obviously learned very different things from different companies.I would say that Yahoo was just the learning in cloud to begin with because prior to joining Yahoo, I wasn't familiar with Silicon Valley cloud companies at that scale and Yahoo is a big company and there's a lot to learn from there. It was also my first introduction to Hadoop, Spark, and even machine learning where I really got into machine learning at scale, in online advertising and areas like that, which was a massive scale. And I got into that in Yahoo, and it was personally exciting to me because there's very few opportunities where you can work on machine learning at that scale, right?Databricks was very exciting to me because it was an earlier-stage company than I had been at before. Extremely well run and I learned a lot from Databricks, just the team, the culture, the focus on innovation, and the focus on product thinking. I joined Databricks as a product manager. I hadn't played the product manager hat before that, so it was very much a learning experience for me and I think I learned from some of the best in that area. And even at Pinecone, I carry that forward, which is think about how my learnings at Databricks informs how we should be thinking about products at Pinecone, and so on. So, I think I learned—if I had to pick one company I learned a lot from, I would say, it's Databricks. The most [unintelligible 00:23:50].Corey: I would also like to point out, normally when people say, “Oh, the one company I've learned the most from,” and they pick one of them out of their history, it's invariably the most recent one, but you left there in 2018—Ram: Yeah.Corey: —then went to go spend the next three years over at Splunk, where you were a Senior Principal, Scientist, a Senior Director and Head of Machine-Learning, and then you decided, okay, that's enough hard work. You're going to do something easier and be the VP of Engineering, which is just wild at a company of that scale.Ram: Yeah. At Splunk, I learned a lot about management. I think managing large teams, managing multiple different teams, while working on very different areas is something I learned at Splunk. You know, I was at this point in my career when I was right around trying to start my own company. Basically, I was at a point where I'd taken enough learnings and I really wanted to do something myself.That's when Edo and I—you know, the CEO of Pinecone—and I started talking. And we had worked together for many years, and we started working together at Yahoo. We kept in touch with each other. And we started talking about the sort of problems that I was excited about working on and then I came to realize what he was working on and what Pinecone was doing. And we thought it was a very good fit for the two of us to work together.So, that is kind of how it happened. It sort of happened by chance, as many things do in Silicon Valley, where a lot of things just happen by network and chance. That's what happened in my case. I was just thinking of starting my own company at the time when just a chance encounter with Edo led me to Pinecone.Corey: It feels from my admittedly uninformed perspective, that a lot of what you're doing right now in the vector database area, it feels on some level, like it follows the trajectory of machine learning, in that for a long time, the only people really excited about it were either sci-fi authors or folks who had trouble explaining it to someone without a degree in higher math. And then it turned into—a couple of big stories from the mid-2010s stick out at me when we've been people were trying to sell this to me in a variety of different ways. One of them was, “Oh, yeah, if you're a giant credit card processing company and trying to detect fraud with this kind of transaction volume—” it's, yeah, there are maybe three companies in the world that fall into that exact category. The other was WeWork where they did a lot of computer vision work. And they used this to determine that at certain times of day there was congestion in certain parts of the buildings and that this was best addressed by hiring a second barista. Which distilled down to, “Wait a minute, you're telling me that you spent how much money on machine-learning and advanced analyses and data scientists and the rest have figured out that people like to drink coffee in the morning?” Like, that is a little on the ridiculous side.Now, I think that it is past the time for skepticism around machine learning when you can go to a website and type in a description of something and it paints a picture of the thing you just described. Or you can show it a picture and it describes what is in that picture fairly accurately. At this point, the only people who are skeptics, from my position on this, seem to be holding out for some sort of either next-generation miracle or are just being bloody-minded. Do you think that there's a tipping point for vector search where it's going to become blindingly obvious to, if not the mass market, at least more run-of-the-mill, more prosaic level of engineer that haven't specialized in this?Ram: Yeah. It's already, frankly, started happening. So, two years back, I wouldn't have suspected this fast of an adoption for this new of technology from this varied number of use cases. I just wouldn't have suspected it because I, you know, I still thought, it's going to take some time for this field to mature and, kind of, everybody to really start taking advantage of this. This has happened much faster than even I assumed.So, to some extent, it's already happening. A lot of it is because the barrier to entry is quite low right now, right? So, it's very easy and cost-effective for people to create these embeddings. There is a lot of documentation out there, things are getting easier and easier, day by day. Some of it is by Pinecone itself, by a lot of work we do. Some of it is by, like, companies that I mentioned before who are building better and better models, making it easier and easier for people to take these machine-learning models and use them without having to even fine-tune anything.And as technologies like Pinecone really mature and dramatically become cost-effective, the barrier to entry is very low. So, what we tend to see people do, it's not so much about confidence in this new technology; it is connecting something simple that I need this sort of value out of, and find the least critical path or the simplest way to get going on this sort of technology. And as long as it can make that barrier to entry very small and make this cost-effective and easy for people to explore, this is going to start exploding. And that's what we are seeing. And a lot of Pinecone's focus has been on ease-of-use, in simplicity in connecting the zero-to-one journey for precisely this reason. Because not only do we strongly believe in the value of this technology, it's becoming more and more obvious to the broader community as well. The remaining work to be done is just the ease of use and making things cost-effective. And cost-effectiveness is also what the focus on a lot. Like, this technology can be even more cost-effective than it is today.Corey: I think that it is one of those never-mistaken ideas to wind up making something more accessible to folks than keeping it in a relatively rarefied environment. We take a look throughout the history of computing in general and cloud in particular, were formerly very hard things have largely been reduced down to click the button. Yes, yes, and then get yelled at because you haven't done infrastructure-as-code, but click the button is still possible. I feel like this is on that trendline based upon what you're saying.Ram: Absolutely. And the more we can do here, both Pinecone and the broader community, I think the better, the faster the adoption of this sort of technology is going to be.Corey: I really want to thank you for spending so much time talking me through what it is you folks are working on. If people want to learn more, where's the best place for them to go to find you?Ram: Pinecone.io. Our website has a ton of information about Pinecone, as well as a lot of standard documentation. We have a free tier as well where you can play around with small data sets, really get a feel for vector search. It's completely free. And you can reach me at Ram at Pinecone. I'm always happy to answer any questions. Once again, thanks so much for having me.Corey: Of course. I will put links to all of that in the show notes. This promoted guest episode is brought to us by our friends at Pinecone. Ram Sriharsha is their VP of Engineering and R&D. And I'm Cloud Economist Corey Quinn. If you've enjoyed this podcast, please leave a five-star review on your podcast platform of choice, whereas if you've hated this podcast, please leave a five-star review on your podcast platform of choice along with an angry, insulting comment that I will never read because the search on your podcast platform is broken because it's not using a vector database.Corey: If your AWS bill keeps rising and your blood pressure is doing the same, then you need The Duckbill Group. We help companies fix their AWS bill by making it smaller and less horrifying. The Duckbill Group works for you, not AWS. We tailor recommendations to your business and we get to the point. Visit duckbillgroup.com to get started.Announcer: This has been a HumblePod production. Stay humble.
Real-time analytics are difficult to achieve because large amounts of data must be integrated into a data set as that data streams in. As the world moved from batch analytics powered by Hadoop into a norm of “real-time” analytics, a variety of open source systems emerged. One of these was Apache Pinot. StarTree is a The post Pinot and StarTree with Chinmay Soman appeared first on Software Engineering Daily.
© 2020-2026 Ivy Podcast Discovery LLC

